GNU/Linux distributions include a wealth of programs for handling text, most of which are provided by the GNU core utilities. There’s somewhat of a learning curve, but these utilities can prove very useful and efficient when used correctly.
Here are thirteen powerful text manipulation tools every command-line user should know.
1. cat
Cat was designed to concatenate files but is most often used to display a single file. Without any arguments, cat reads standard input until Ctrl + D is pressed (from the terminal or from another program output if using a pipe). Standard input can also be explicitly specified with a -.
Cat has a number of useful options, notably:
-Aprints “$” at the end of each line and displays non-printing characters using caret notation.-nnumbers all lines.-bnumbers lines that are not blank.-sreduces a series of blank lines to a single blank line.
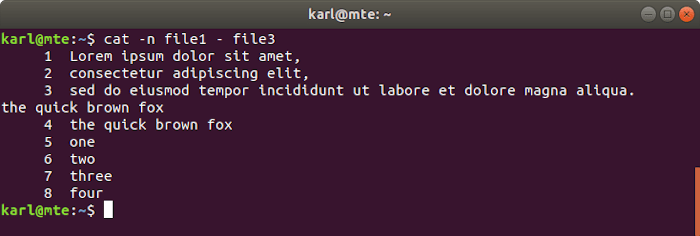
In the following example, we are concatenating and numbering the contents of file1, standard input, and file3.
cat -n file1 - file3
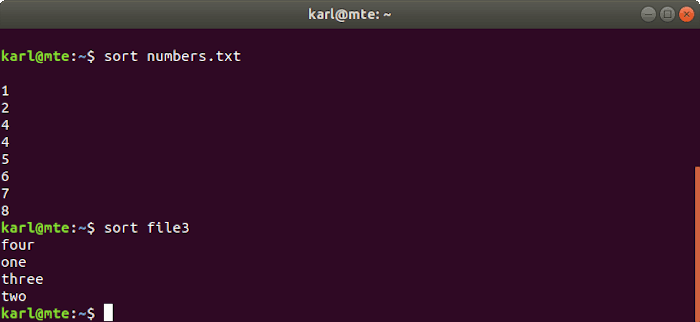
2. sort
As its name suggests, sort sorts file contents alphabetically and numerically.
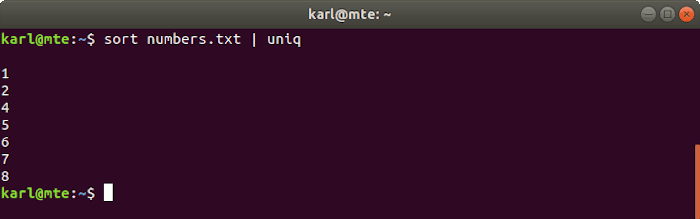
3. uniq
Uniq takes a sorted file and removes duplicate lines. It is often chained with sort in a single command.
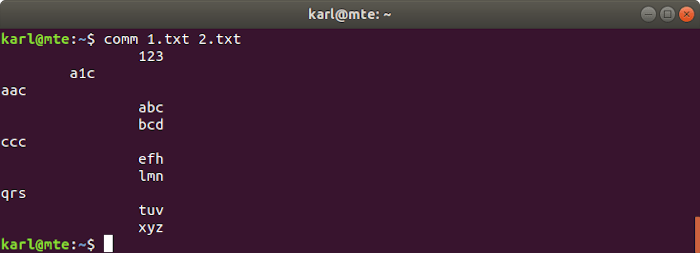
4. comm
Comm is used to compare two sorted files, line by line. It outputs three columns: the first two columns contain lines unique to the first and second file respectively, and the third displays those found in both files.
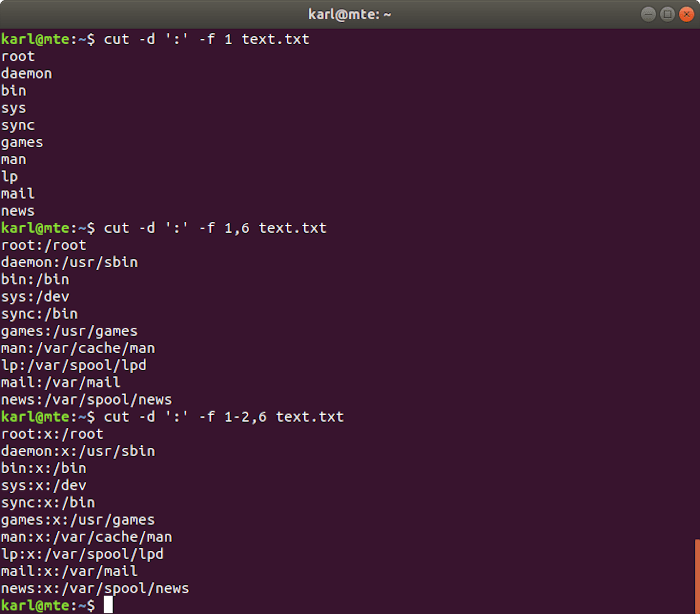
5. cut
Cut is used to retrieve specific sections of lines, based on characters, fields, or bytes. It can read from a file or from standard input if no file is specified.
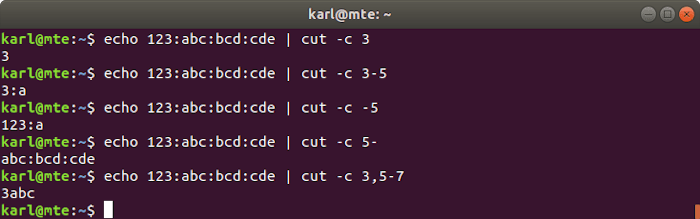
Cutting by character position
The -c option specifies a single character position or one or more ranges of characters.
For example:
-c 3: the 3rd character.-c 3-5: from the 3rd to the 5th character.-c -5or-c 1-5: from the 1st to the 5th character.-c 5-: from the 5th character to the end of the line.-c 3,5-7: the 3rd and from the 5th to the 7th character.
Cutting by field
Fields are separated by a delimiter consisting of a single character, which is specified with the -d option. The -f option selects a field position or one or more ranges of fields using the same format as above.
6. dos2unix
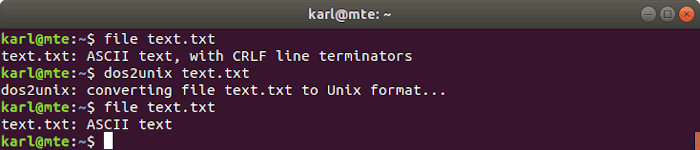
GNU/Linux and Unix usually terminate text lines with a line feed (LF), while Windows uses carriage return and line feed (CRLF). Compatibility issues can arise when handling CRLF text on Linux, which is where dos2unix comes in. It converts CRLF terminators to LF.
In the following example, the file command is used to check the text format before and after using dos2unix.
7. fold
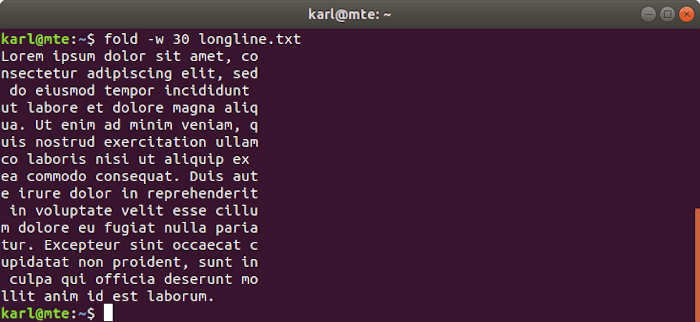
To make long lines of text easier to read and handle, you can use fold, which wraps lines to a specified width.
Fold strictly matches the specified width by default, breaking words where necessary.
fold -w 30 longline.txt
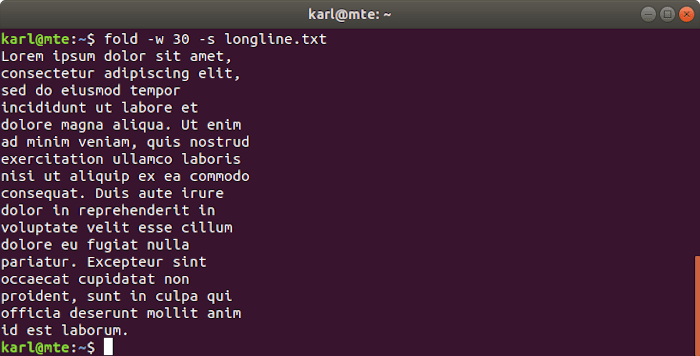
If breaking words is undesirable, you can use the -s option to break at spaces.
fold -w 30 -s longline.txt
8. iconv
This tool converts text from one encoding to another, which is very useful when dealing with unusual encodings.
iconv -f input_encoding -t output_encoding -o output_file input_file
- “input_encoding” is the encoding you are converting from.
- “output_encoding” is the encoding you are converting to.
- “output_file” is the filename iconv will save to.
- “input_file” is the filename iconv will read from.
Note: you can list the available encodings with iconv -l
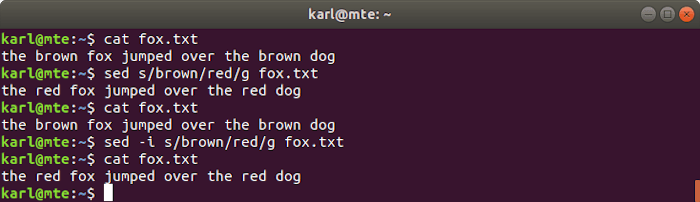
9. sed
sed is a powerful and flexible stream editor, most commonly used to find and replace strings with the following syntax.
The following command will read from the specified file (or standard input), replacing the parts of text that match the regular expression pattern with the replacement string and outputting the result to the terminal.
sed s/pattern/replacement/g filename
To modify the original file instead, you can use the -i flag.
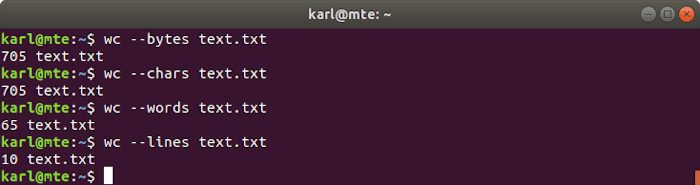
10. wc
The wc utility prints the number of bytes, characters, words, or lines in a file.
11. split
You can use split to divide a file into smaller files, by number of lines, by size, or to a specific number of files.
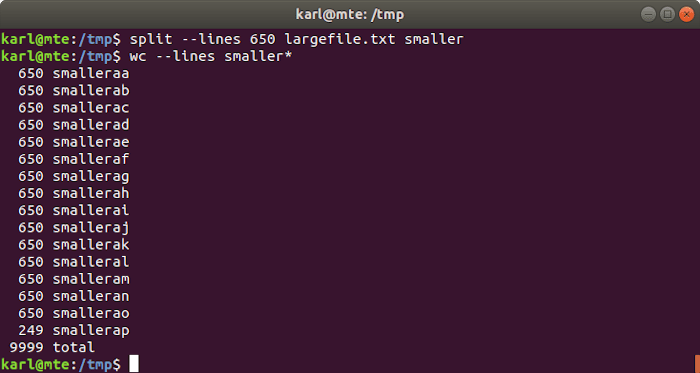
Splitting by number of lines
split -l num_lines input_file output_prefix
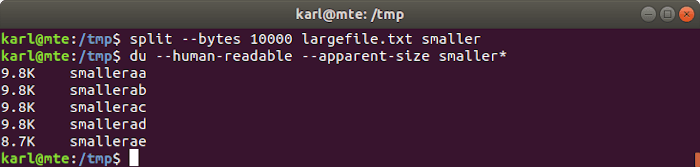
Splitting by bytes
split -b bytes input_file output_prefix
Splitting to a specific number of files
split -n num_files input_file output_prefix

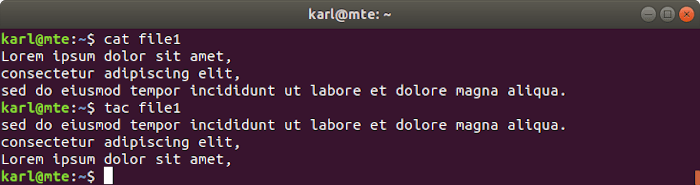
12. tac
Tac, which is cat in reverse, does exactly that: it displays files with the lines in reverse order.
13. tr
The tr tool is used to translate or delete sets of characters.
A set of characters is usually either a string or ranges of characters. For instance:
- “A-Z”: all uppercase letters
- “a-z0-9”: lowercase letters and digits
- “\n[:punct:]”: newline and punctuation characters
Refer to the tr manual page for more details.
To translate one set to another, use the following syntax:
tr SET1 SET2
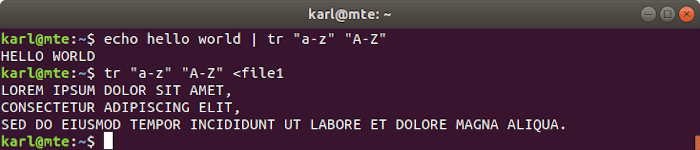
For instance, to replace lowercase characters with their uppercase equivalent, you can use the following:
tr "a-z" "A-Z"
To delete a set of characters, use the -d flag.
tr -d SET

To delete the complement of a set of characters (i.e. everything except the set), use -dc.
tr -dc SET

Conclusion
There is plenty to learn when it comes to Linux command line. Hopefully, the above commands can help you to better deal with text in the command line.