
Ever wanted to create your own AI images without the hassle of online generators? While free, most online options limit the images you can create and often require a subscription after a few tries. Enter Stable Diffusion, a free, open-source AI image generator that lets you create images at home without restrictions.
What Is Stable Diffusion?
Stable Diffusion is a free, open-source model that turns text into images by generating pictures from your descriptions. It’s not a standalone program, but a core technology that other apps use. While there are several ways to use generative AI, especially for image generation, Stable Diffusion stands as one of the best. Among other methods to generate free AI images, Stable Diffusion continues to have endless support. This guide covers three ways to use Stable Diffusion, from simple to advanced, each with its own set of features.
System Requirements
The rough guidelines for what you should aim for are as follows:
- macOS: Apple Silicon (an M series chip)
- Windows or Linux: NVIDIA or AMD GPU
- RAM: 16GB for best results
- GPU VRAM: at least 4GB (8GB Recommended)
- Storage: 60-70GB
1. Using Automatic1111 WebUI
The first method is to use the AUTOMATIC1111 Web UI program to access Stable Diffusion. It is available across all major desktop operating systems.
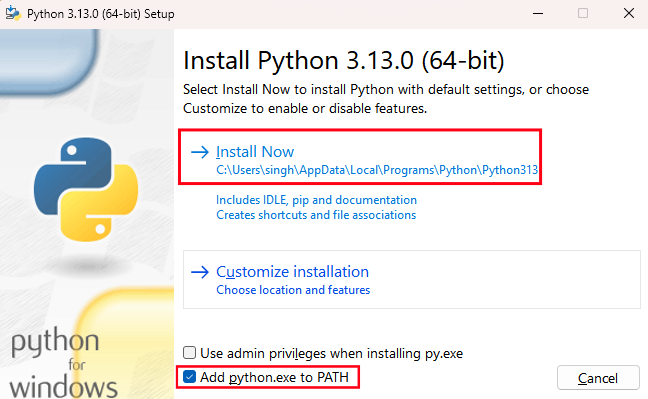
Download the latest stable version of Python. Once downloaded, run the Python installer, and ensure that you check Add python.exe to PATH before clicking Install Now.
Go to the AUTOMATIC1111 Web UI repository on GitHub, click Code, and then click Download ZIP. Wait for the download to finish, unzip the file, and make a note of where you have installed the WebUI program.
Install a Model
You’ll still need to add at least one model before you can start using the Web UI. Models are pre-trained checkpoints that dictate the generation of images in a particular style. For installing any model that you like, head on over to CIVITAI, and pick a model.
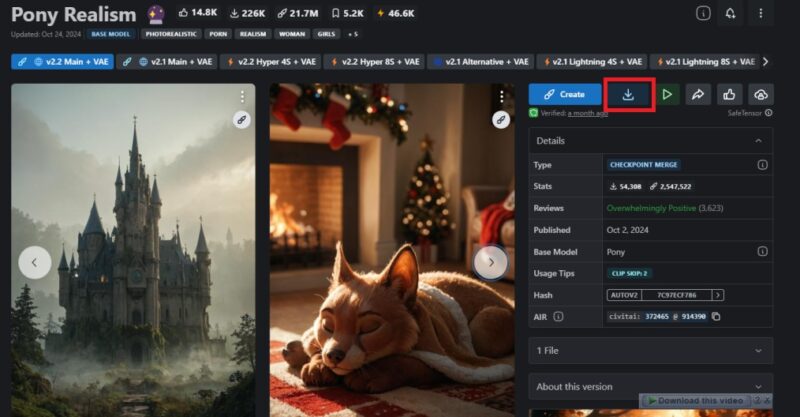
Once you find a model with the art style you prefer, hit the download button. When the download finishes, move the ‘.safetensors’ checkpoint file into the right place. For this, locate the download folder for your Automatic1111 WebUI. Then, go to webui -> models -> Stable-diffusion. Simply paste the model you’ve downloaded here and you’re off to the races.
Run and Configure WebUI
At this point, you’re ready to run and start using the Stable Diffusion program in your web browser.
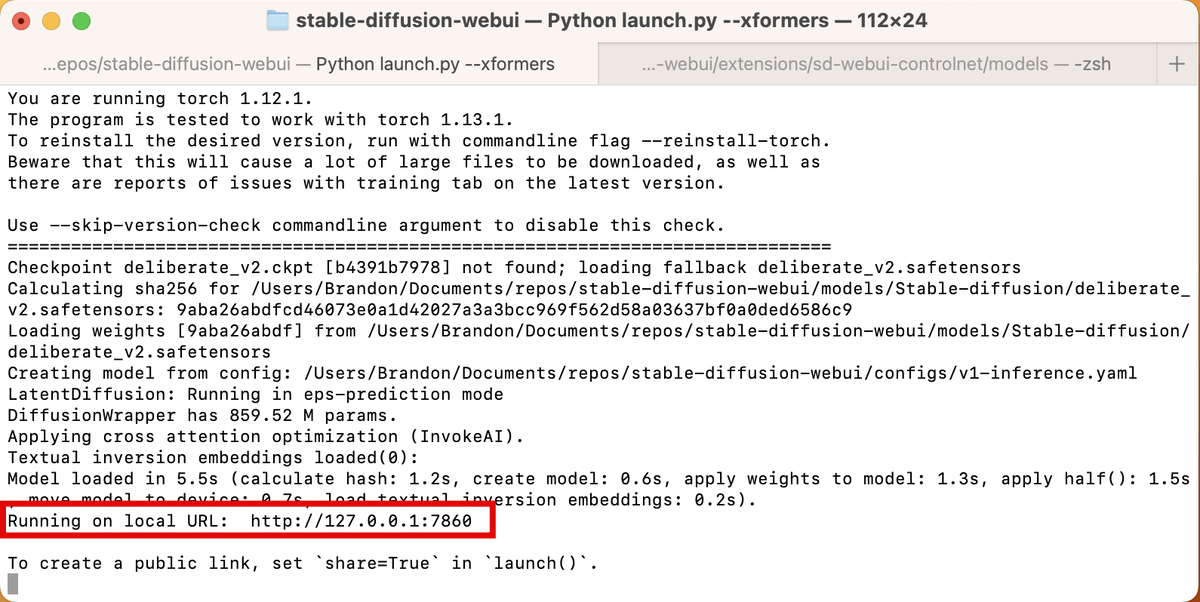
On macOS, open your “stable-diffusion-webui” directory in Terminal, and enter the command ./webui.sh --xformers. For Windows, you need to enter ./webui-user.bat. When it’s finished, select and copy the URL next to “Running on local URL”, which should look like http://127.0.0.1:7860.
Paste the link in your browser address bar and hit Enter. The Web UI website will appear, running locally on your computer’s default internet browser. While the initial interface might seem daunting, you don’t need to fiddle too much with the settings to begin with.
For starters, you can set the Width and Height settings and change the batch size to 4. This would create four separate images for each prompt.
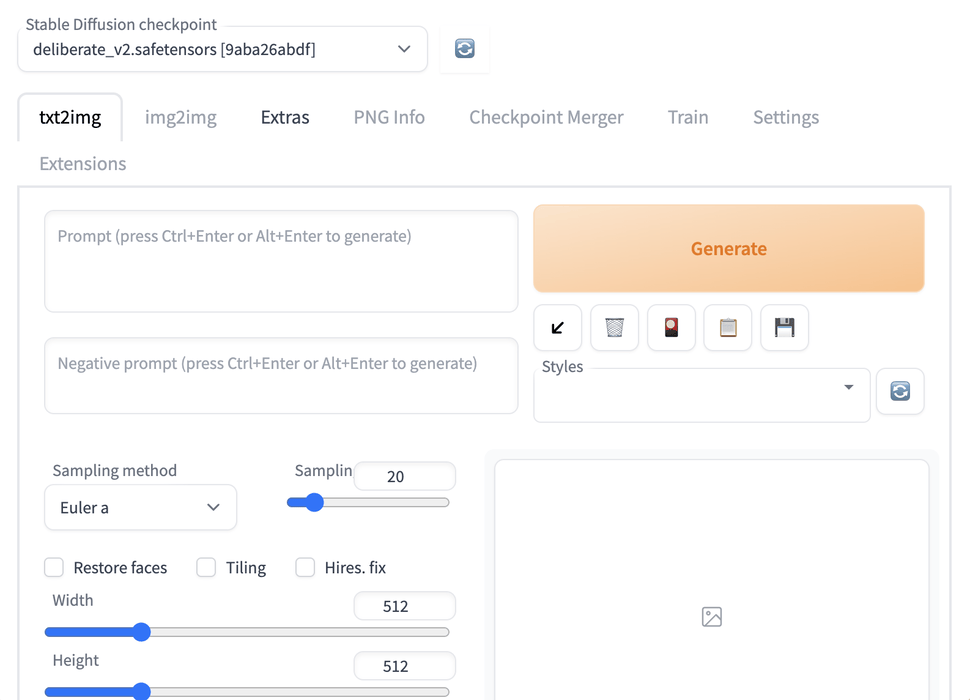
Now comes the fun part: creating some AI generated images. You can put in any prompt that comes to mind in the txt2img tab. Make sure you describe the image you want, separating different descriptions with commas. Plus, describe the style of the image as well, using words like ‘realistic’, ‘detailed’, or ‘close-up portrait’.
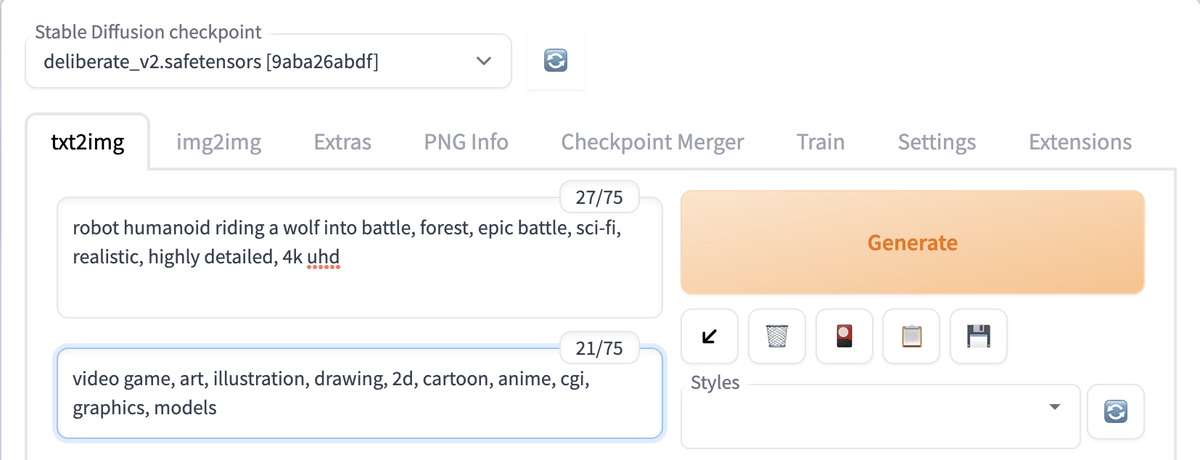
In the negative prompt text box below, type keywords that you do not want your image to look like. A good setting to change is the “CFG Scale”. A higher CFG Scale value will make the image generator stick closer to your prompt. On the other hand, a lower value will produce more creative images.
Leaving other settings as they are, click Generate at the top for Stable Diffusion to start working. Once done, click the image thumbnails to preview them and determine whether you like any of them. If not, simply tweak the CFG Scale options and your prompts. It is during the image generation phase that your GPU would be pushed to its limit.

If you like one image overall but want to modify it or fix issues (a distorted face, anatomical issues, etc.), click either Send to img2img or Send to inpaint. This will copy your image and prompts over to the respective tabs where you can improve the image.
2. Using Fooocus, The Simplest AI Image Generator
Fooocus is one of the simplest and most efficient AI image generators available. Its user-friendly interface makes image generation easy to start and master, making it the perfect program for beginning your AI image journey before trying more advanced methods.
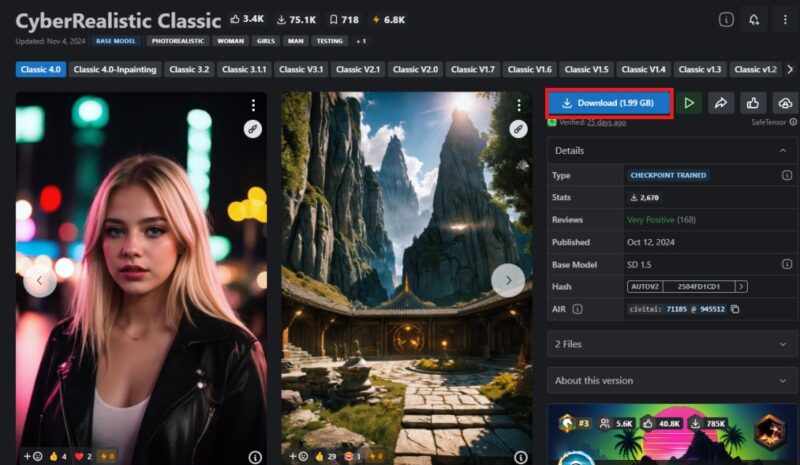
Download Fooocus from its Github page. This will download the compressed Fooocus file, which you have to extract once the download completes. Next, head to CIVITAI and download a checkpoint you like. Once you have downloaded the checkpoint, head to your Fooocus directory. From there, click Fooocus -> models -> checkpoints, and paste the checkpoint file you just downloaded.
You can download LoRAs from Civitai – small files that adapt large language models with just one new concept or style. Unlike checkpoints, which are several gigabytes, LoRAs work off an existing checkpoint to add a unique touch to the final image.
If you do download a LoRA to enhance the visual style of your AI images, head to the same models folder of your Fooocus directory, and paste the LoRA file into the loras folder.
Running Fooocus
It’s time to begin generating images in Fooocus. Head to the directory where you extracted the software, and click run.bat. Wait for the command prompt terminal to show up and load. It should automatically open the Fooocus interface, running locally in your web browser.
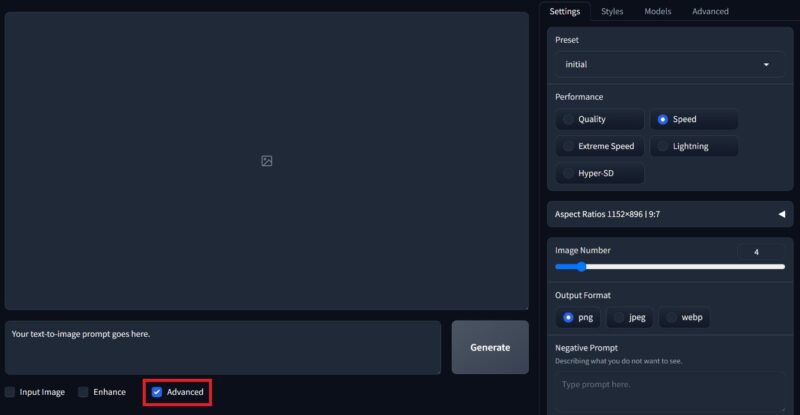
From the initial screen, check the Advanced box on the bottom, which will open advanced settings. Here, select the aspect ratio you want for your images, and the number of images Fooocus will generate per prompt. You can also select the file format of the images.
To start with, keep the performance selected to Speed. This is what makes Fooocus generate images incredibly fast. The negative prompt for elements you do not want in your images is at the bottom here.
After checking Advanced, you can check out the Styles tab for different styles you wish to lend to your images. Hover over each style to preview it. Next, head to the Models tab, and select the base model. This will pick the checkpoint you placed in your Fooocus directory. Right underneath, select a LoRA of your choice from the directory.
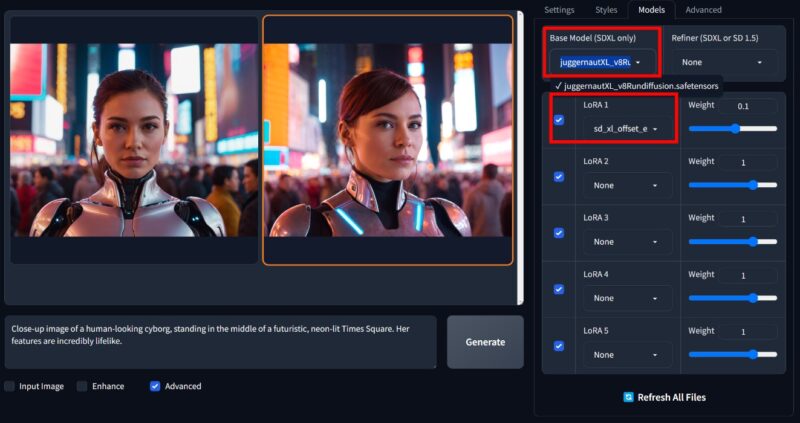
All that’s left is to hit the Generate button, and watch Fooocus work its magic. Inarguably the simplest method out there to generate images and tweak them, Fooocus might not be the most powerful. However, it clearly is the most efficient method. With Fooocus as your AI image generator, you can keep fiddling with styles, checkpoints, and LoRAs to generate images as per your liking.
Using AI Face Swap in Fooocus
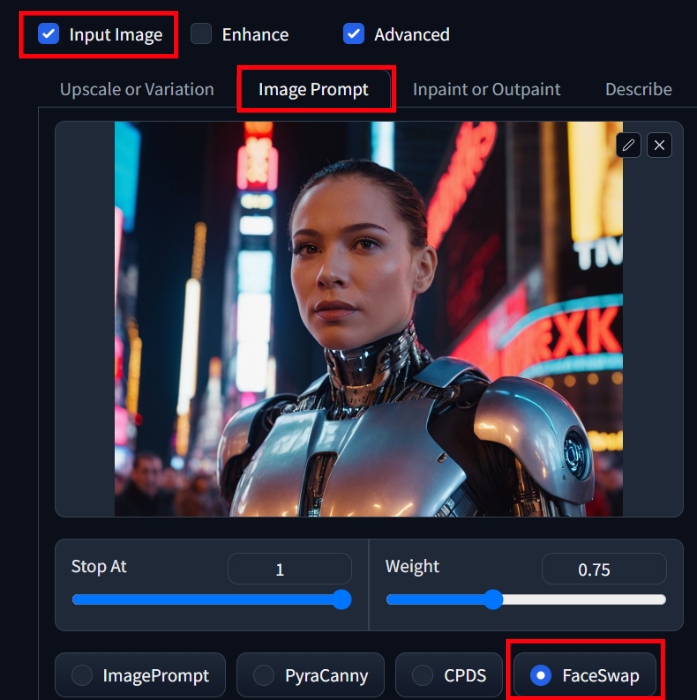
Fooocus even includes FaceSwap, where you can swap the faces in one image for another. For this, check the Input Image box at the bottom, and select Image Prompt. Here, upload the image you wish to swap your AI image’s face with. Scroll down, click Advanced again, and from the options now present under your uploaded face, select FaceSwap.
Now, right next to the Image Prompt tab, click on the Inpaint or Outpaint tab, and upload the image you wish to swap faces with. Draw over the face and the hair, and move to the Advanced tab on the top-right. Select Developer Debug Mode, click on Control, and check Mixing Image Prompt and Inpaint.
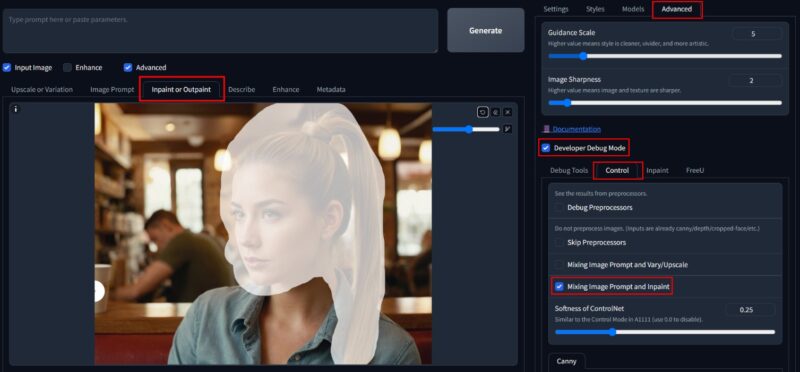
Then, simply empty the prompt box, and hit Generate. This will face swap your image with the target picture, with varying results.

With your images out and ready, you can always run them through some of the best AI image upscaling tools. This helps increase the resolution of the image you have generated.
3. Using ComfyUI to Generate AI Images
ComfyUI is another popular method for using Stable Diffusion to generate AI images. The ComfyUI workflow might be the most interesting, but it is also the most complicated. To get started, download and extract ComfyUI from Github.
By now, you are already familiar with checkpoints and loras. As explained in the other methods, download a checkpoint file (and a LoRA file if you want), and place it in the appropriate folders in the models directory inside ComfyUI. Once in the ComfyUI directory, the first thing to do is to open the Update folder. Run update_comfyui.bat, and you’re ready to go.
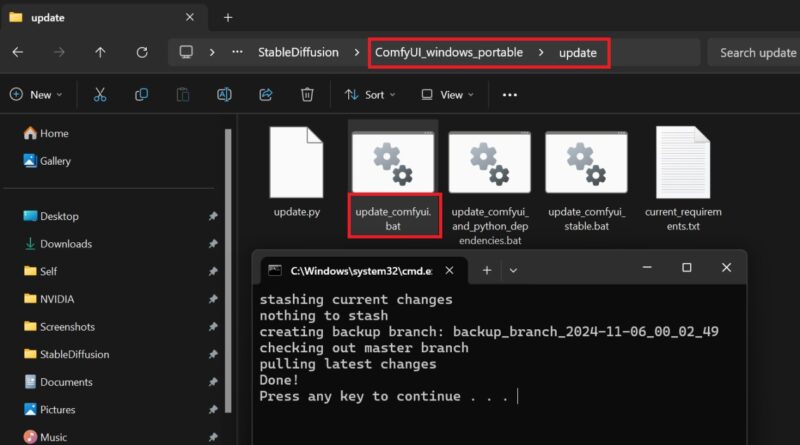
Now, it is time to run the ComfyUI AI image generator. Head to your ComfyUI directory, and you should see two batch files. If you have an Nvidia GPU in your system, double-click the run_nvidia_gpu.bat file. Otherwise, select and run run_cpu.bat.
Once ComfyUI loads into your browser, you will see the default workflow of ComfyUI. There are several nodes connecting to each other. While they might look confusing at first, these nodes are just visual representations of each step of the AI image generation process.
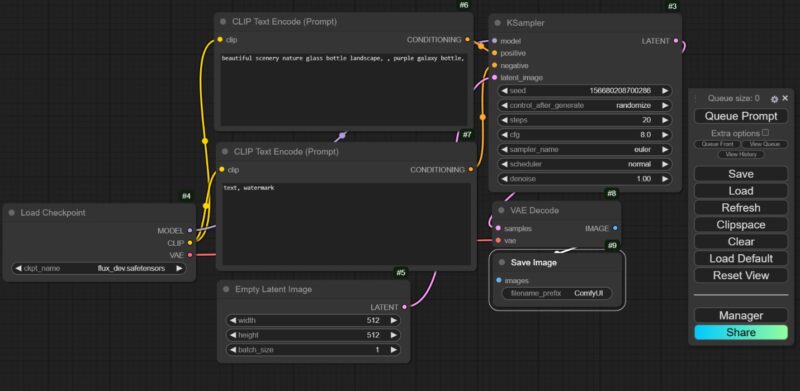
Multiple nodes allow you to create your very own workflow, combining different nodes, models, LoRAs, and refiners. This gives the use extreme control over the final result. However, they also make ComfyUI difficult to understand and master.
Running ComfyUI
To start off, you select a checkpoint into the Load Checkpoint node. Next, move to the CLIP Text Encode (Prompt) node. This is where you put in your text prompt for the image. Right below it, there is a node with the same name. This is the negative prompt, describing unwanted elements. In the Empty Latent Image node, you can select the width, height, and number of images.
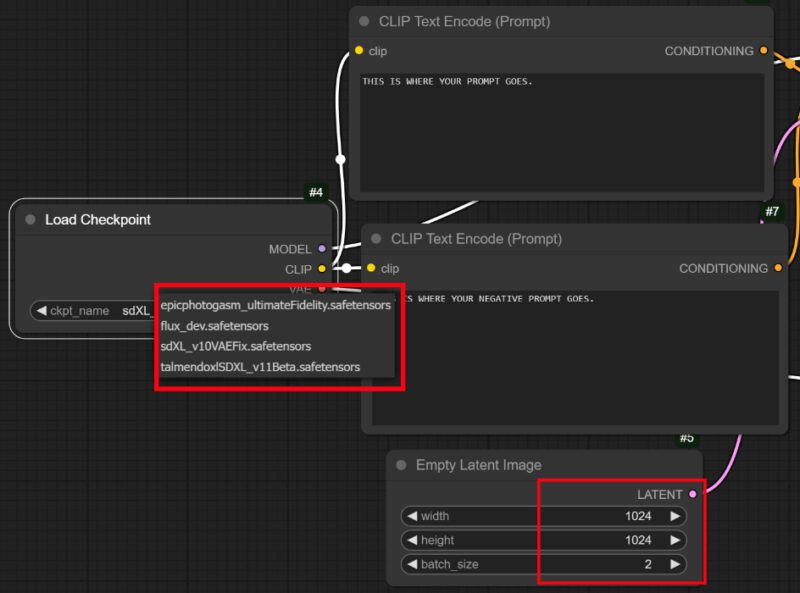
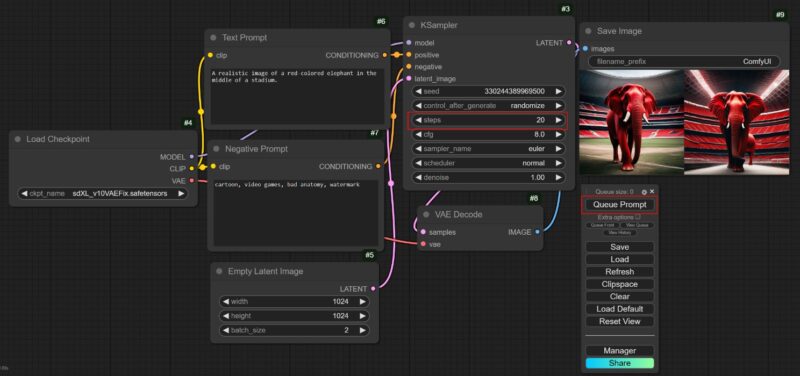
Once you get your positive and negative prompts, tweak the dimensions of the image, the batch size, and select the number of steps. Anything between 20 and 30 is a good amount of steps for a good-quality image to come out. Lastly, just hit the Queue Prompt button, and wait for ComfyUI to work.
Using LoRAs in ComfyUI
If there are certain LoRAs you wish to use in ComfyUI, you just have to right-click anywhere near the checkpoint node. Select Add Node -> loaders -> Load LoRA, and pick any LoRA from your LoRAs folder in the directory.
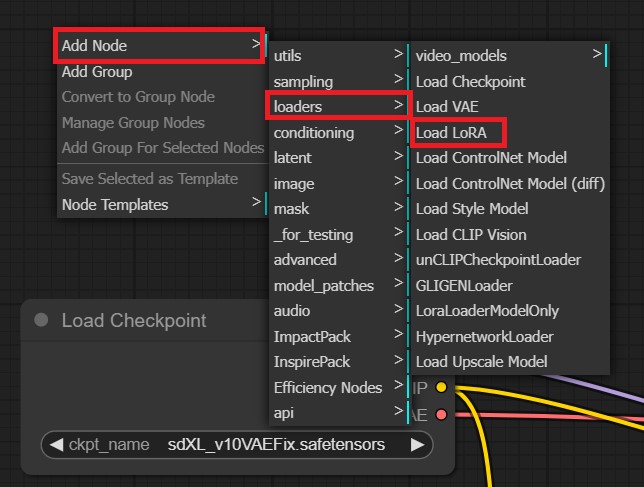
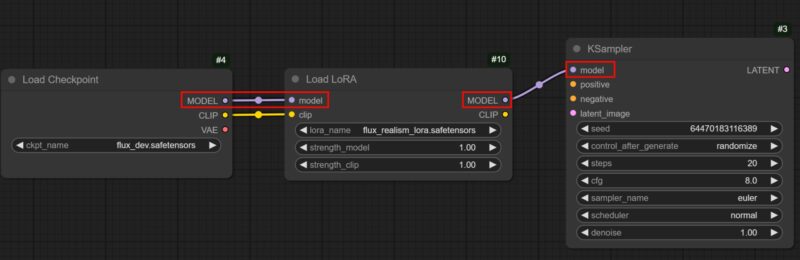
However, in ComfyUI, every time you load a new LoRA node, you have to move things around. Carefully click-and-drag the line going from the Checkpoint node titled Model. Now, instead of letting it go into KSampler, move the line to attach into the LoRA node’s model point on the left instead. Then, click on the exiting Model point of the LoRA node and connect it to the KSampler’s entry model point.
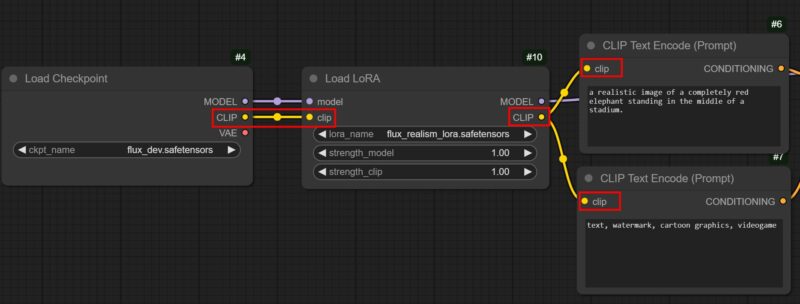
Now, there are two Clip lines exiting from the Checkpoint node into each Prompt node. Make both of those lines attach into the LoRA’s Clip entry point on the left. Then, simply replicate what you saw, drawing one line each from the LoRA’s Clip into both your positive and negative prompt nodes.
With all of these nodes combined, you can become familiar with the default workflow, only adding one custom node at a time as you learn and progress.
Frequently Asked Questions
What is the difference between Stable Diffusion, DALL-E, and Midjourney?
All three are AI programs that can create images from text prompts. However, only Stable Diffusion is completely free and open-source. You can intall and run it on your computer free-of-cost. On the other hand, DALL-E and Midjourney are both close-source.
What is a model in Stable Diffusion?
A model is a file representing an AI algorithm trained on specific images and keywords. Different models are better at creating different types of images. While some models may create the best realistic images of people, others may be better at creating 2D images or other styles.
Image credit: Feature Image by Stable Diffusion. All screenshots by Brandon Li and Samarveer Singh.







