If you’ve been following terminal-focused installation instructions for Linux applications for a while, you’ve probably come across the curl command at some point or another. cURL is a command-line tool for transferring data with URLs. One of the simplest uses is to download a file via the command line. This is deceptive, however, as cURL is an incredibly powerful tool that can do much more.
Also read: How to Copy and Paste Text, Files and Folders in Linux Terminal
What Is cURL?
Originally written by Daniel Sternberg in 1996 to grab financial data from web servers and broadcast it to IRC channels, cURL has evolved to become a powerful tool for getting data without having to use a browser. If you’re always using the terminal, this will be one of the more important tools in your arsenal.
In most Linux distributions, cURL is preinstalled in the system, and you can use it straight away. Even if it is not installed, it is also found in most repositories, so you can easily install it using the Software Center.
For Windows, it does not have a “curl-like” command, and macOS has cURL preinstalled but doesn’t offer quite as many flags as the Linux version.
Also read: How to Use the dd Command in Linux
Installation
Before we proceed any further, we have to make sure that cURL is already installed on our system.
Linux
In Debian/Ubuntu-based distros, use the following command to install cURL:
sudo apt install curl
In Arch-based distros:
sudo pacman -S curl
In Fedora/CentOS/RHEL:
sudo dnf install curl
macOS
For macOS, it is already preinstalled, so you don’t need to do anything.
Also read: How to Launch Terminal in the Current Folder Location on Mac
Windows
- For Windows 7/10/11, head over to the cURL download page and choose from either the 64-bit or 32-bit packages, according to the architecture you’re running. If you don’t know your architecture, 64-bit is a safe bet, as the vast majority of hardware made after 2006 is on it.
- Create a folder either directly on the system drive or in “C:\Program Files\” and call it “cURL.”
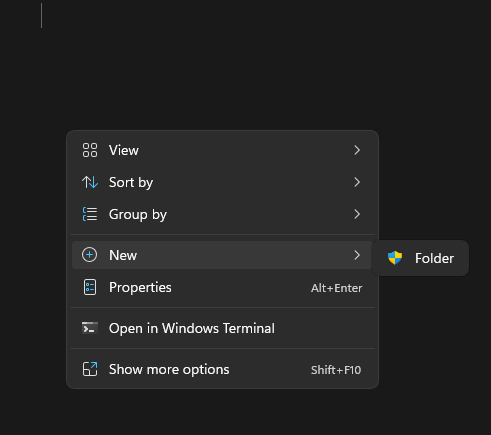
- Go back to the zip file you downloaded, open it, and find “curl.exe” inside the “bin” folder. Copy that to the cURL folder you created. The EXE you copied is completely self-contained and capable of running every permutation you can run on Linux.
- To make this command actually useful, we have to add it to the PATH variable in Windows so that it can run from the command prompt anywhere.
- Click on your Start menu, type
environment, and press Enter. - Click on “Environment Variables … ” You should now be in your environment variables settings.
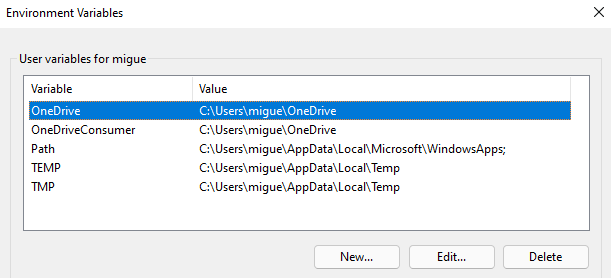
- Select the “Path” environment variable, then click “Edit … “
- Once in the path edit dialog window, click “New” and type out the directory where your “curl.exe” is located – for example, “C:\Program Files\cURL”.
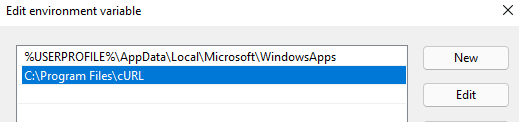
- Click “OK” on the dialog windows you opened through this process and enjoy having cURL in your terminal!
Every flag in cURL that’s usable in Linux should work in the Windows version.
Word to the wise: remember that the command prompt should never be confused with Windows Terminal. Windows Terminal comes with its own version of cURL included in the PowerShell that serves similar functionality but works entirely differently.
Also read: How to Use Rm Command in Linux
Using cURL
To get started, simply type curl maketecheasier.com in your terminal and press Enter.
If you are not getting any output, it is because this site’s server is not configured to respond to random connection requests to its non-www domain. If you polled a server that doesn’t exist or isn’t online, you’d get an error message saying that cURL could not resolve the host.

To get cURL to do something actually useful, we’ll have to specify a protocol. In our example, we are using the HTTPS protocol to query this site’s home page. Type curl https://maketecheasier.com.
If all goes well, you should be staring at a gigantic wall of data. To make that data a bit more usable, we can tell cURL to put it into an HTML file:
curl https://maketecheasier.com > ~/Downloads/mte.html

This command puts the contents of our site’s output into an HTML file in your Downloads folder. Navigate to the folder with your favorite file manager and double-click the file you just made. It should open a snapshot of the HTML output of this site’s home page.

Similarly, you can use the -o flag to achieve the same result:
curl -o ~/Downloads/mte.html https://maketecheasier.com
Following Redirects
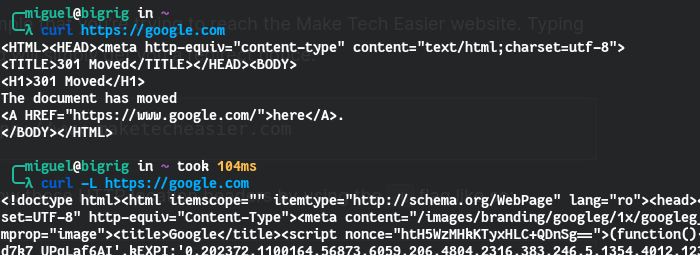
Most sites automatically redirect the traffic from “http” to “https” protocol. In cURL, you can achieve the same thing with the -L flag. This will automatically follow 301 redirects until it reaches a readable page or file.
curl -L http://google.com.
Resuming a Download
When downloading large files, depending on your Internet speed, interruptions can be immensely irritating. Thankfully, cURL has a resume function. Passing the -C flag will take care of this issue in a jiffy.
To show a real-world example, I interrupted a download of Debian’s testing release ISO on purpose by pressing Ctrl and C in the middle of grabbing it.
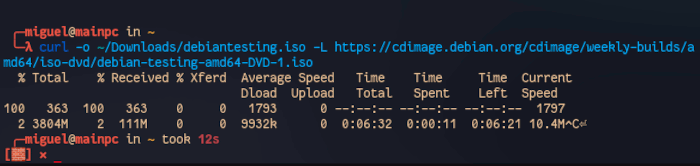
For our next command, are attching the -C flag. For example,
curl -C - -o ~/Downloads/debiantesting.iso -L https://cdimage.debian.org/cdimage/weekly-builds/amd64/iso-dvd/debian-testing-amd64-DVD-1.iso
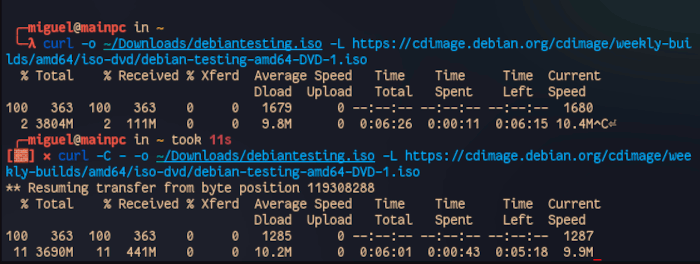
The download successfully started where it left off.
Downloading More than One File
Because cURL doesn’t have the most intuitive way to download multiple files, there are two methods, each one with its own compromise.
If the files you’re downloading are enumerated (e.g., file1, file2, and so on), you can use brackets to get the full range of files and “#” within the output you specify with the -o flag. To make this a bit less confusing, here’s an example:
curl "http://example.com/file[1-5].zip" -o "#1_#2"
A simpler way of doing this is with -O (--remote-name). This flag makes cURL download the remote file onto a local file of the same name. Since you don’t have to specify an output, you should use this command when the terminal is open in the directory you want to download files to.
curl -O "https://example.com/file1.zip" -O "https://example.com/file2.zip"
If you have a large amount of enumerated files to download, --remote-name-all is a better flag for this:
curl --remote-name-all "https://example.com/file[1-5].zip"
You could even specify non-enumerated files coming from the same site without having to re-type the URL using brackets:
curl --remote-name-all "https://example.com/{file1.zip,anotherfile.zip,thisisfun.zip}"
Downloading with Authentication
Download files that require authentication (for example, when grabbing from a private FTP server) with the -u flag. Every authentication request must be done with the username first and the password second, with a colon separating the two. Here’s an example to make things simple:
curl -u username:password -o ~/Downloads/file.zip ftp://example.com/file.zip
This will authenticate our friend bonobo_bob into the FTP server and download the file into the Downloads folder.
Splitting and Merging Files
If for any reason you wish to download a large file and split it into chunks, you can do so with cURL’s --range flag. With --range, you must specify the byte you want to start at up to the one you want to finish at. If you do not specify an end to the range, it will just download the rest of the file.
In the command below, cURL will download the first 100 MB of Arch Linux’s installation image:
curl --range 0-99999999 -o arch.part1 -L https://mirrors.chroot.ro/archlinux/iso/2021.11.01/archlinux-2021.11.01-x86_64.iso
For the next 100 MB, use --range 100000000-199999999, etc. You can chain these commands by using the && operand:
curl --range 0-99999999 -o arch.part1 -L https://mirrors.chroot.ro/archlinux/iso/2021.11.01/archlinux-2021.11.01-x86_64.iso && \ curl --range 100000000-199999999 -o arch.part2 -L https://mirrors.chroot.ro/archlinux/iso/2021.11.01/archlinux-2021.11.01-x86_64.iso && \ curl --range 200000000-299999999 -o arch.part3 -L https://mirrors.chroot.ro/archlinux/iso/2021.11.01/archlinux-2021.11.01-x86_64.iso && \ curl --range 300000000-399999999 -o arch.part4 -L https://mirrors.chroot.ro/archlinux/iso/2021.11.01/archlinux-2021.11.01-x86_64.iso && \ curl --range 400000000-499999999 -o arch.part5 -L https://mirrors.chroot.ro/archlinux/iso/2021.11.01/archlinux-2021.11.01-x86_64.iso && \ curl --range 500000000-599999999 -o arch.part6 -L https://mirrors.chroot.ro/archlinux/iso/2021.11.01/archlinux-2021.11.01-x86_64.iso && \ curl --range 600000000-699999999 -o arch.part7 -L https://mirrors.chroot.ro/archlinux/iso/2021.11.01/archlinux-2021.11.01-x86_64.iso && \ curl --range 700000000- -o arch.part8 -L https://mirrors.chroot.ro/archlinux/iso/2021.11.01/archlinux-2021.11.01-x86_64.iso
If you followed the above command structure to the letter, eight files should appear where you asked cURL to download them.

To reunite these files, you’ll have to use the cat command if you’re on Linux or macOS like so:
cat arch.part? > arch.iso
For Windows, you’ll have to use the copy command like this:
copy /b arch.part* arch.iso
Other Useful Features
There are plenty of flags and uses for cURL:
-#– Uses a progress bar to indicate how far along you are in what you’re grabbing. Example:curl -# https://asite.com/somefile.zip > ~/somefile.zip.-a– Asks cURL to append to a file rather than overwrite it. Example:curl -ao ~/collab-full.x https://example-url.com/collab-part26.x.--head– Only grabs the response header from the server without the output data. This is useful when you’re either debugging a website or having a peek at the server’s programmed responses to clients. Example:curl --head https://example-url.com.--limit-rate– Orders a download with limited bandwidth. It’s useful in situations where you don’t want cURL hogging all the available bandwidth in your system. A simple number will be interpreted as bytes per second. K represents kilobytes per second; M represents megabytes per second. Example:curl --limit-rate 8M https://example-url.com/file.zip > ~/file.zip.-o– As mentioned earlier, determines an output file for cURL to use. Example:curl -o ~/Downloads/file.zip https://thefileplace.com/file.zip -o file2.zip https://thefileplace.com/file2.zip.--proxy– If you want to work with a proxy, this is the way to do it. Example:curl --proxy proxyurl:port https://example-url.com/file.zip > ~file.zip.
cURL vs. Wget
Both released in the same year (1996), cURL and Wget are pretty much sister programs to the casual observer. Dive a little deeper, though, and you can see these two sisters have different purposes.
Wget
- It’s fully built from the ground up to grab data from the Internet.
- Doesn’t need the
-Lor-oflags like cURL; just typewget [url]and go! - Can download recursively to grab everything in a directory with the
-rflag. - Has all the functions a user needs for daily use and caters to everyday sysadmin tasks.
- (In Linux) Doesn’t need many dependencies; all of them should be available out of the box.
Also read: How to Install and Use wget on Mac
cURL
- Expansive repertoire of flags and useful functions for remote retrieval.
- Supports local networking (LDAP) and network printers (Samba).
- Works well with gzip compression libraries.
- Depends on libcurl, which allows developers to write software or bash scripts that include cURL’s functionality.
In short, Wget is the “everyman’s toolbox” for grabbing stuff from the Internet, while cURL expands on this with more granulated control for power users and system administrators.
Frequently Asked Questions
1. I got a certificate error in Linux. How do I fix it?
If you got an error that says something like “peer’s certificate issuer has been marked as not trusted,” the easiest way to fix this is by reinstalling the common certificates package in your distro.
For Debian/Ubuntu-based systems:
sudo apt reinstall ca-certificates
For Fedora/CentOS/RHEL:
dnf reinstall ca-certificates
For Arch-based systems:
pacman -S ca-certificates
Note that in Arch you may want to clear your package cache using pacman -Scc before reinstalling the certificates package.
If you still get this error, there may be something wrong on the server’s end.
2. Is it safe to run cURL and bash commands together?
While not the most common way to install Linux applications, there are a number of developers (such as the people behind NodeJS) that give you no choice but to use curl alongside a root-access command that runs through bash (e.g., curl [argument] | sudo -E bash -) to install the software.
It may look a bit scary, but if the people behind the application are trustworthy, it’s very unlikely you’ll break something. Malicious actors are everywhere and can infiltrate repositories like Arch’s AUR, so installing using curl in combination with root access commands isn’t generally more unsafe than doing so through your package manager.
3. Can I use cURL with Tor?
Yes! Start Tor Browser (or a standalone tor service) and use the --proxy flag. Tor gives you a local proxy you can use to mask your IP in other applications. Here’s an example of cURL used with Tor:
curl --proxy localhost:9050 http://example.com
Standalone Tor services will use 9050 as their listening port, while the Tor browser uses port 9150.
Wrapping Up
cURL has proven resilient amid the changing fabric of the Linux world, keeping its position as an important tool in the terminal user’s arsenal.
If you are new to the command line, check out some of the most useful Linux commands. If you simply want to search the Web instead of downloading data from the Internet, you can browse on the terminal too.