Have you ever tried to find a recurring pattern in a piece of text? You might have used something like the search function in your browser or word processor, but when you need to find something more complex, it can be like finding a needle in the proverbial haystack.
Fortunately, there’s a way to pick out precise patterns in text right down to the character. It’s called regular expressions (RegEx), and it lets you become a master of searching through text.
Also read: How to Use Regular Expressions to Improve Productivity in Your Daily Tasks
Where can I use RegEx?
Although Unix and Linux made them popular, regular expressions are available in a variety of packages, including Microsoft Word.
Regular expressions are most notably used in several notable Linux programs, including grep, Awk and Sed.
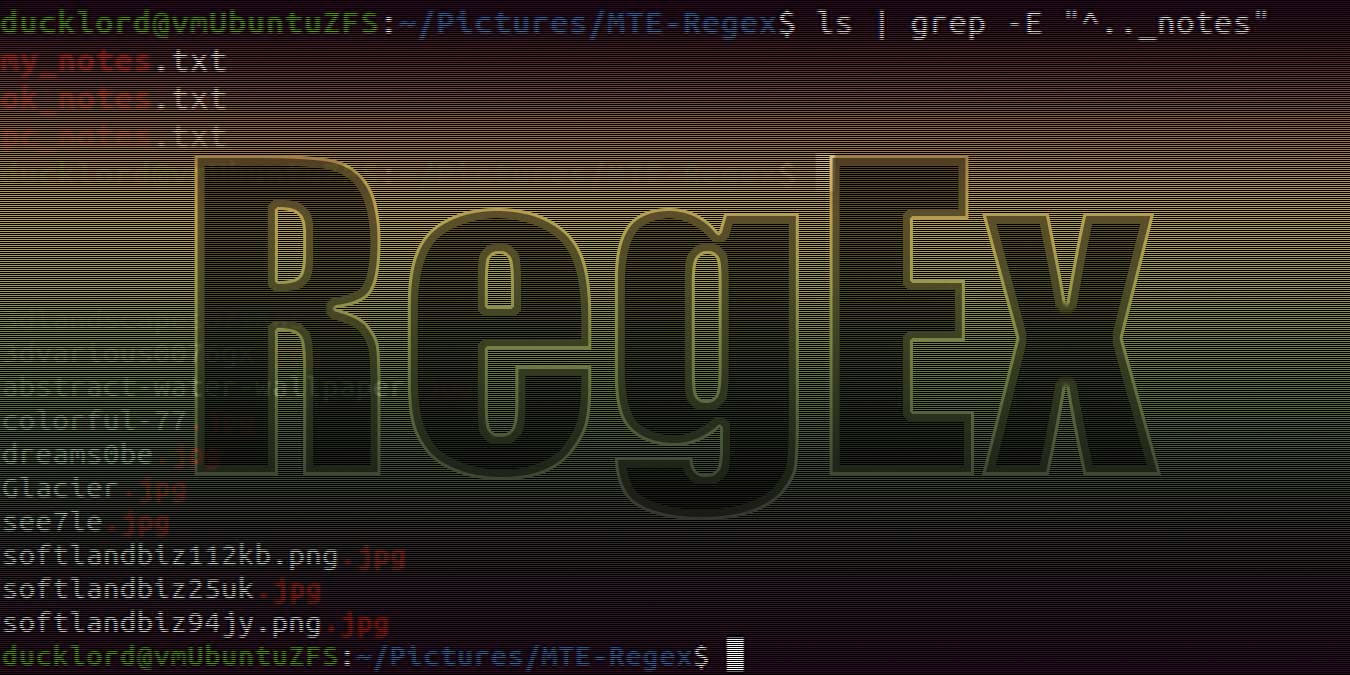
For example, you may want to check the USB devices on your PC. Using lspci, you’ll see a list of all devices, and you’ll have to locate the USB entries by yourself. You could instead use the following to only show the USB devices:
lspci | grep "USB"
This is the simplest example of RegEx in action. It’s the most popular way of using regular expressions in the terminal but not the only one. Today you can find RegEx support in many different types of software, from text editors to file managers.
Finding Patterns
You’ve probably used the * character, which acts as a wildcard when selecting files or folders in the terminal. For example, to list all JPG files in a folder, you could use:
ls *.jpg
The RegEx equivalent of the above would be:
ls | grep -E "\.jpg"

To search for both jpg and png files, use:
ls | grep -E "(\.jpg|\.png)"
Ranges
If you want to search for a specific range of characters instead of a pattern, you can do that by defining it in brackets. If, for example, you use [a-z] as your pattern, this would match any string consisting of any lowercase letters of the alphabet.
As you might have guessed, [A-Z] would select only uppercase letters. To choose any range of letters, in both uppercase and lowercase, the expression would change to [a-zA-Z].
To locate a specific number of instances of your pattern, you can state it in curly brackets. {5} would return five occurrences of your pattern. You can also use ranges of numbers, so {5,10} would present you with five to ten instances.
MetaCharacters
In regular expressions, you can also search for parts of a string with two characters called metacharacters. They’re similar to the wildcard matches you might have used in the shell.
The primary one is the simple dot, which stands for any other single character. If you used the pattern c.ll, it would match “cell” but also “cull” and “call.”
By entering an asterisk after a dot, you can use it to match an infinite number of characters. For example, .*board will be a match for both “keyboard” and “skateboard.” even if “key” and “skate” have a different number of letters.
Escape
You might have noticed that in our example, where we selected different types of image files, we used backslashes before the period (“\.jpg”). That’s how you escape special characters in RegEx.
If we didn’t use them, our pattern wouldn’t match only the extensions of the files, strings like “.jpg” and “.png,” but would also match “ajpg” and “opng.” Remember, . is a wildcard that matches any character.
Anchors and Boundaries
Anchors and boundaries allow you to define more precisely what you are seeking.
To find only the individual word “computer,” with no other characters attached before or after, you should define the pattern as \.
You can also search specifically for patterns that appear at the beginning or the end of the line. This is achieved with the ^ and $ characters respectively.
So, if you wanted to find only the entries where the word “computer” appeared at the beginning of a line, your pattern would look like ^computer. For the opposite, when it is at the end of the line, the pattern would change to computer$.
Those are RegEx’s simple rules, which you can also mix to find precisely the patterns you’re seeking. You can search for character ranges at the beginning of a line or alternating words at the end, specific dates, or a range of years, using a single string of text.
Don’t forget to check out our Regular Expressions cheatsheet to master regular expressions.