The terminal is the heart of a Linux system. Every program that runs in Linux is running underneath a terminal command line. This includes massive programs, such as web browsers and even simple ones such as text editors. As such, being able to properly use the terminal is an important step if you want to understand how the operating system works.
With that, while working on the Linux terminal, you may want to save the terminal output of a command to a file. This file may be used as information for another operation or to simply log terminal activity. This article teaches five ways to save the terminal output to a file.
Also read: How to Use the dd Command in Linux
1. Use Specific Terminals
The first way of dealing with this is by using a Terminal that supports saving the output to a file. For example, the Konsole terminal that comes with a standard KDE installation includes an option to write the output to a file.
To do that, press the “File” button in the menu bar and click “Save output as … “
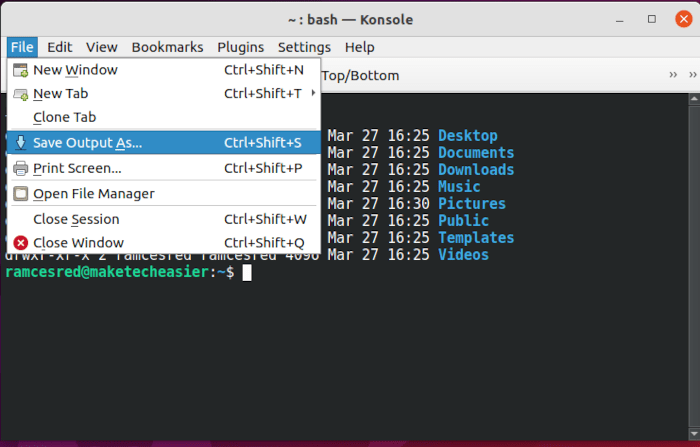
This will open a window dialog where you can save the terminal output. From there, you can pick where you want to save the file.
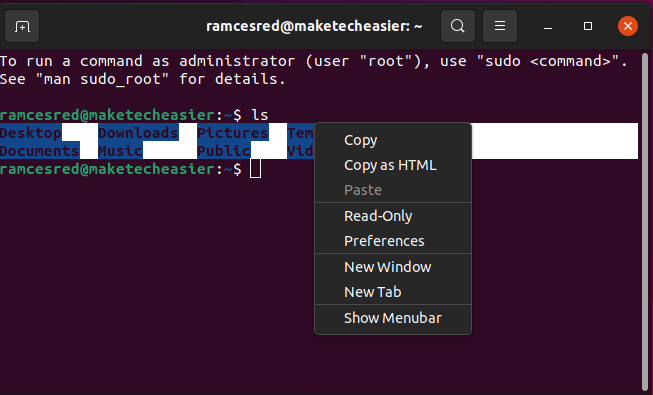
You can also save the output of a command in GNOME terminal. Simply right-click on the terminal and press “Copy output as HTML.” This will, then, load the terminal text into your clipboard. From there, you can paste it to any text editor.
Also read: How to Use Rm Command in Linux
2. Output Redirection
Another way of dealing with this is to use the built-in operators of the UNIX shell. These are default functions in Linux and can redirect the text output of a program to a file. There are three operators that can do it:
- The
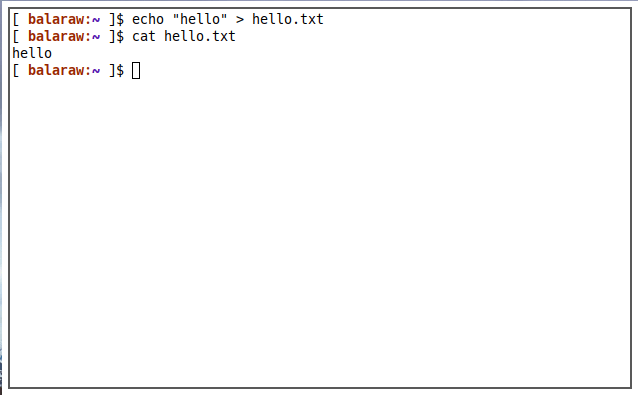
>operator will either create or replace the contents of a file with the output of your program. This is useful if you want to dump and view the current result of your program to the same file. - The
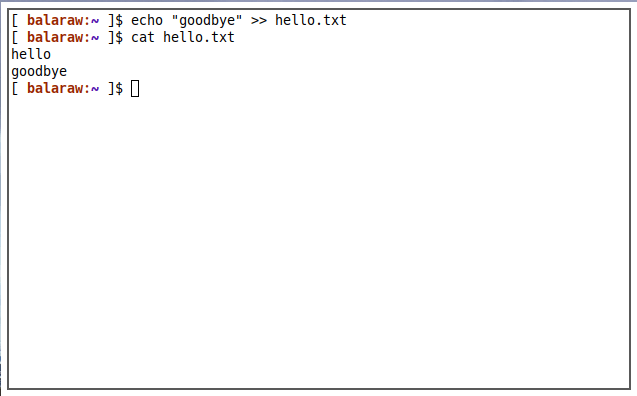
>>operator will also create a file with the output of your program. However, this operator will only append the output instead of replacing it. This is useful if you want to dump the result of your program continuously to a single file. - Lastly, the
2>operator is a special type of operator that will print errors that will be reported back. This is very useful during debugging, as it shows the problem that the program encountered before it crashed.
Knowing that, the way you use these operators is by adding it at the end of your program. Consider the following example:
echo "maketecheasier" > hello.txt
I instructed the echo program to output the word “maketecheasier,” then added the > operator as well as a file name. This told the UNIX shell to write the output to the “hello.txt” file instead of printing it to the screen.
3. Tee
Aside from output redirection, you can also save the output of a terminal command by using a program called tee. This is a GNU program that allows you to read from and write to standard input. Use this program with UNIX pipes to write the output of a command to a file.
Consider the following example:
echo "maketecheasier" | tee hello.txt
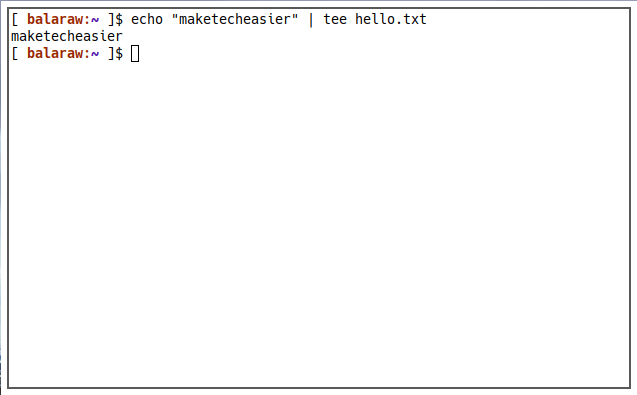
Here, instead of using output redirection, I piped (|) the output to tee.
Note: A pipe takes the output of one program and feeds it into the input of another. This allows you to glue multiple programs together, as long as they are all using standard inputs and outputs.
Also read: How to Fix Can’t Type in Terminal Issue in Linux
4. Script
Another way of pulling the output from the terminal is through script, a built-in Linux program that records everything you type in the terminal as well as its output.
You can use script to record the log of your terminal session in a parsable text format. This is very useful if you want to send an error log online to get support from other people.
To use it, run the following command:
script filename.txt
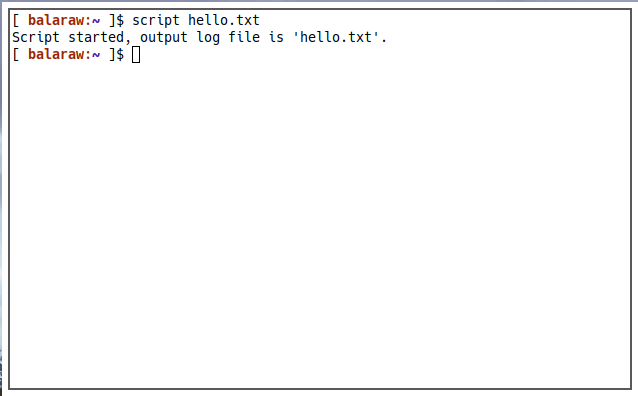
This will start a script environment where you can just start running commands. One important thing to note, however, is that script captures everything you do in that session. Consider the following example:
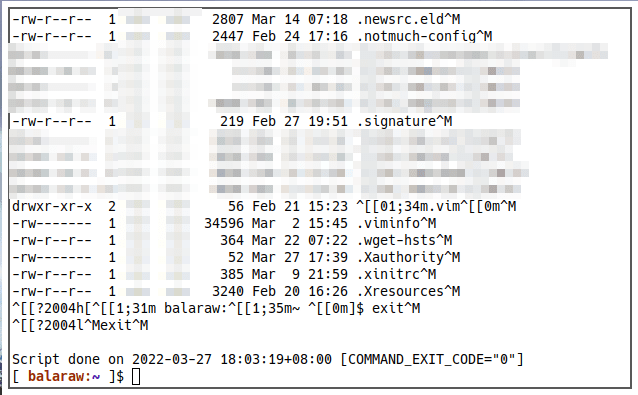
Script started on 2022-03-27 18:02:29+08:00 [TERM="rxvt-unicode-256color" TTY="/dev/pts/2" COLUMNS="77" LINES="22"] [?2004h[[1;31m balaraw:[1;35m~ [0m]$ ls [?2004l [0m[01;34mDesktop[0m [01;34mDownloads[0m [01;34mmail[0m [01;34mNews[0m [01;34mpods[0m [01;34mdocuments[0m [00;32mhello.txt[0m [01;34mMail[0m [01;34mpics[0m [01;34mtmp[0m [01;34mvids[0m [?2004h[[1;31m balaraw:[1;35m~ [0m]$ exit [?2004l exit Script done on 2022-03-27 18:03:19+08:00 [COMMAND_EXIT_CODE="0"]
Script includes all the keypresses and control characters you press. In my case, it included all of the “invisible” keys that I pressed, including Tab and Backspace key presses.
Once you are done with the session, type exit. This will end the Script program and write the whole log to the file that you specified.
Also read: How to Use the lp Command in Linux to Print Files From Terminal
5. Framebuffer Terminal Capture
Lastly, you can also get the output of the terminal by pulling from the Linux framebuffer. This is useful if you are working directly on a teletype and want to capture the output of a program.
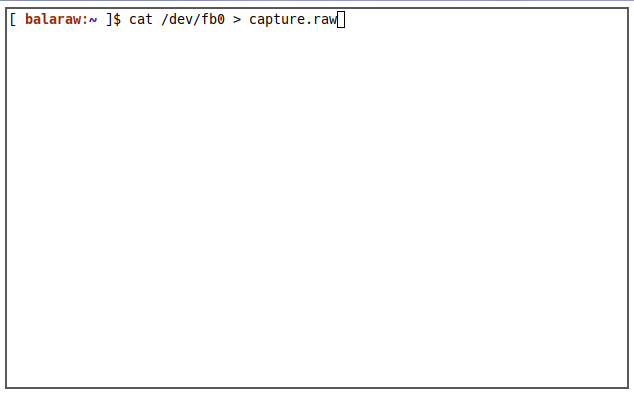
To capture the framebuffer device, run the following command while in the teletype:
cat /dev/fb0 > capture.raw
One important thing to note is that capturing the framebuffer device this way means that you are dumping the raw bytes of the framebuffer into a file. To view that file, you need to load it in an image editor and manually adjust the color and bit depth. Not only is this process time consuming, but it is also easy to do it wrong.
As such, one way to deal with this is by using a third-party program, such as fbgrab. This will grab the current teletype screen from the framebuffer device and dump it into either a PPM or PNG file.
Installing fbgrab is also relatively straightforward. In Debian and Ubuntu-based distributions, you can use apt:
sudo apt install fbgrab
For Arch Linux, run pacman:
sudo pacman -S fbgrab

Using fbgrab to Capture Terminal Output
Once installed, drop to the teletype by pressing Control + Shift + Alt + F3, then run either fbcat or fbgrab.
Fbcat is a simpler program that grabs the current framebuffer screen and saves it to a PPM image. This is a low-level raw image format you can load in an image editor to convert to PNG. Fbcat is primarily useful if you are trying to capture a lower bit-depth display that requires a raw image format to capture properly.
To capture using the fbcat program, run the following command:
fbcat > capture.ppm
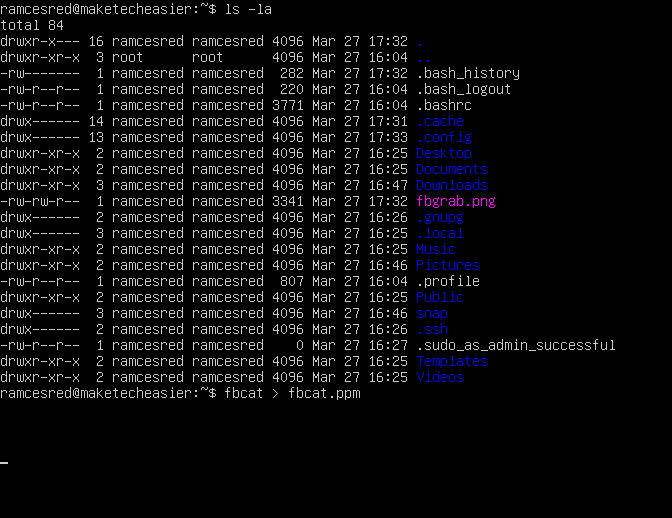
This will grab the currently displayed screen and dump the content in a capture.ppm file.
Fbgrab, on the other hand, is a more complex program designed to capture higher bit-depth displays. For the most part, you will use it to capture your teletype screen. It supports saving to PNG by default and has the option to select a different teletype to capture.
To capture using the fbgrab program, run the following command:
sudo fbgrab -c 3 capture.png
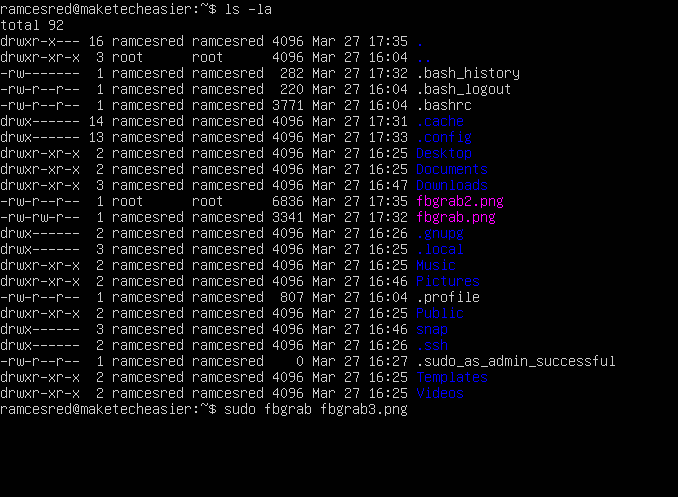
This will grab the third teletype screen and save it in a capture.png file.
If you are looking for more guides for the Linux terminal, check out that discusses sending an email from the command line.
Frequently Asked Questions
1. Help! Fbgrab does not work; the picture is just black or blank.
This is probably because fbgrab is using a different framebuffer device to capture the terminal output. Check the current framebuffer device the system is using by listing the “/dev” folder.
ls /dev
From there, look for a “/dev/fbX” device. Normally, Linux uses “/dev/fb0” for its framebuffer. However, if your system is using a different framebuffer, such as “/dev/fb1”, you can pass the following command to tell fbgrab to pull from that framebuffer instead:
fbgrab -d 1 capture.png
2. Is it possible to grab the content of a file that I wrote as an input to a program?
Yes! Aside from the three operators discussed above, you can also use the operator to pull data from a file. The shell will, then, treat this is an input for a program.
Doing it this way also removes the need to rely on other programs to print the text for you. Consider the following examples:
[1] cat test.txt | program [2] program
- The first example calls the cat program to load the text, then loads a pipe operator with the output of cat and pipes it to your program.
- On the other hand, the second example immediately calls your program, then picks the
operator, which treats the next argument for it as its input.
3. Is there a way to force script to only capture the output of a command?
Yes, it is possible to only script for a single command. This is very useful during troubleshooting when you just want to capture the output of a single program. Do this by running the following command:
script -c "your-command" test.txt
The -c flag tells the script program to only run the program: your-command. From there, it will then write its output in a text file called test.txt.
Image credit: Unsplash