File restoration utilities are one of the most important programs in a Linux administrator’s toolkit. They provide the ability to recover deleted files, even in cases where the disk is either physically damaged or wiped clean.
This guide shows seven simple file recovery tools that you can install right now on Linux. We also show you how you can do basic file restoration on your system.
Restoring a File Using Your File Manager
When you delete a file, only the link between it and its underlying data is deleted. The physical file itself is still intact. It only tells the operating system that the space is now available to be overwritten.
In addition, most desktop environments today prevent you from directly deleting files on your disk. They will instead move the deleted file to a Trash folder (or Recycle bin in Windows), which can then be recovered easily.
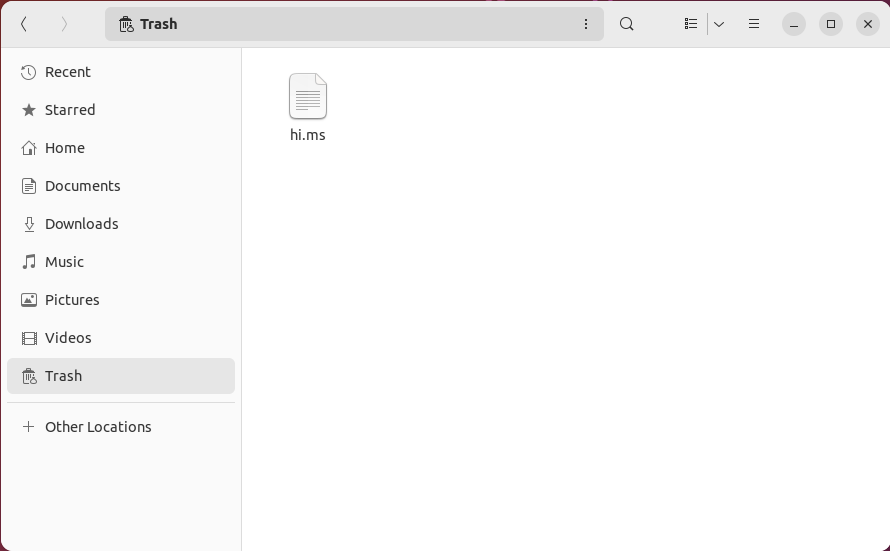
You can recover your files in Linux by accessing your desktop’s Trash folder.
- Press Win, then type “Files.”
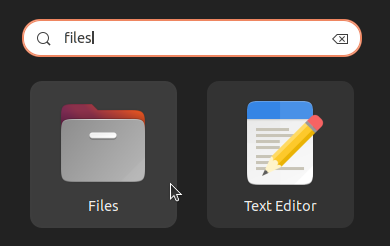
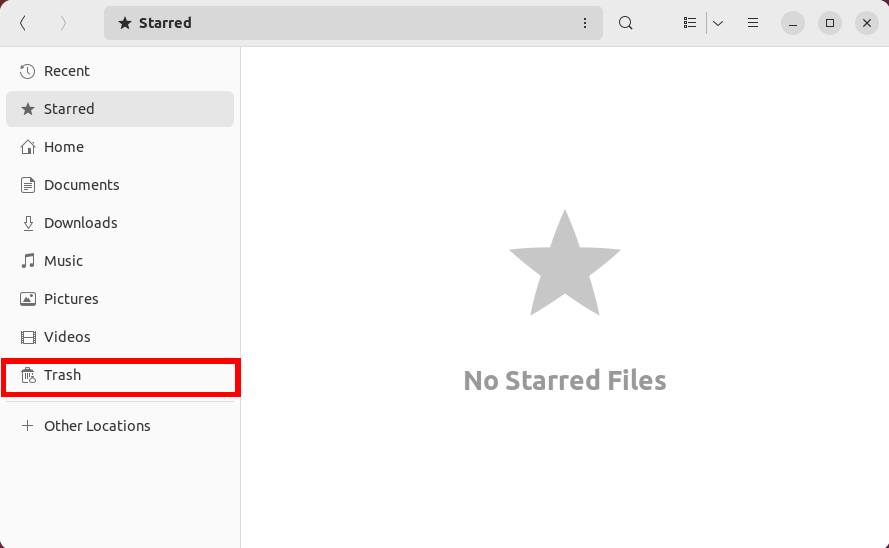
- Click the “Trash” entry on your file manager’s left sidebar.
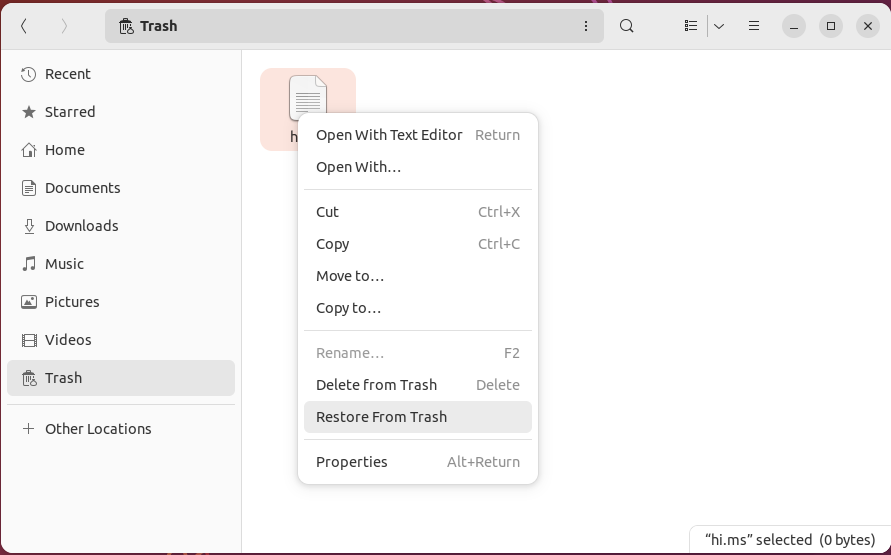
- Right-click the file that you want to restore and select “Restore from Trash.”
Tip: you can also ensure that a file will be impossible to recover by doing proper secure deletion.
1. Testdisk
Testdisk is one of the most popular file recovery tools in Linux. It is a powerful terminal program that can recover missing partitions from almost any disk. It works by going through every cylinder in your disk while looking for any partition table data.
This means that Testdisk can restore a file system even after you have wiped it clean. This can also be helpful in cases where you have accidentally formatted your disk and deleted its internal partition table.
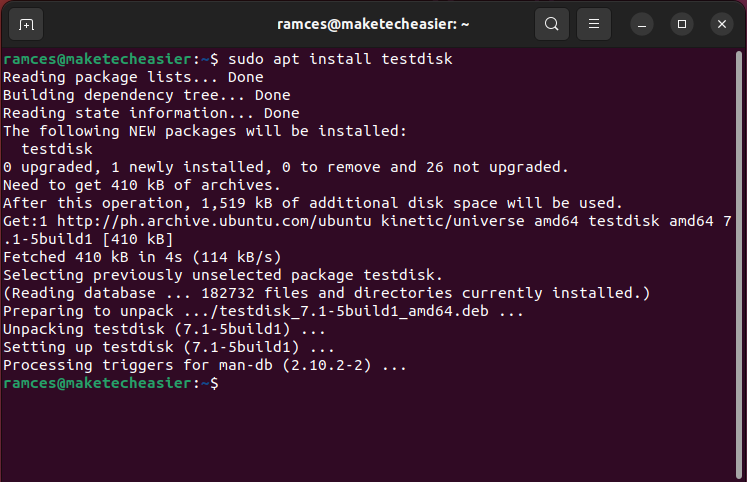
- Install Testdisk in Ubuntu and Debian by running the following command:
sudo apt install testdisk
- Enter
sudo testdiskin your machine’s terminal window to run the program.
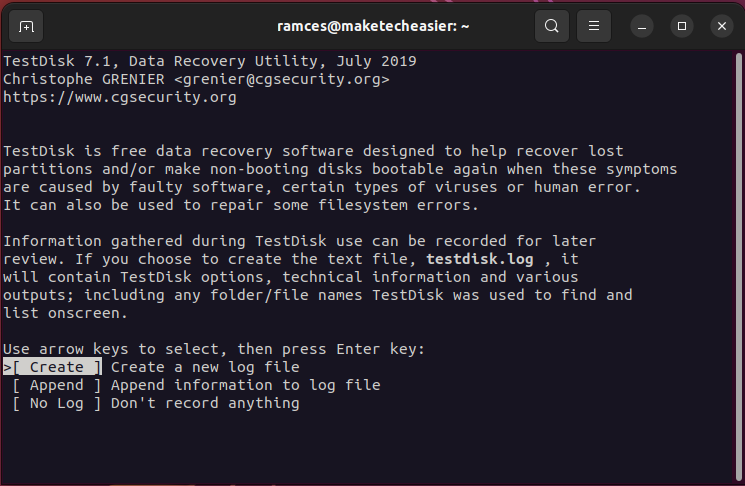
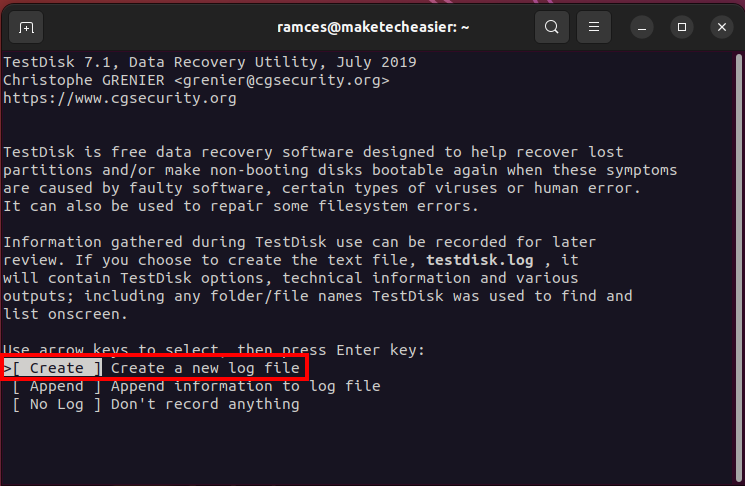
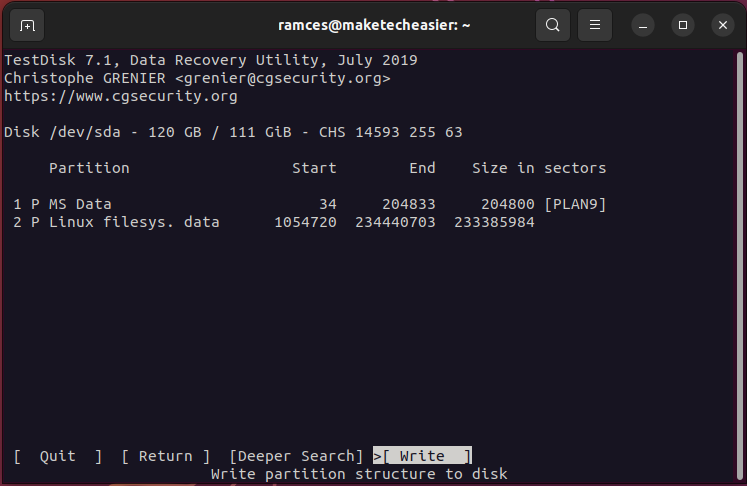
- Select “Create” to tell Testdisk that you want to store a log of the current session.
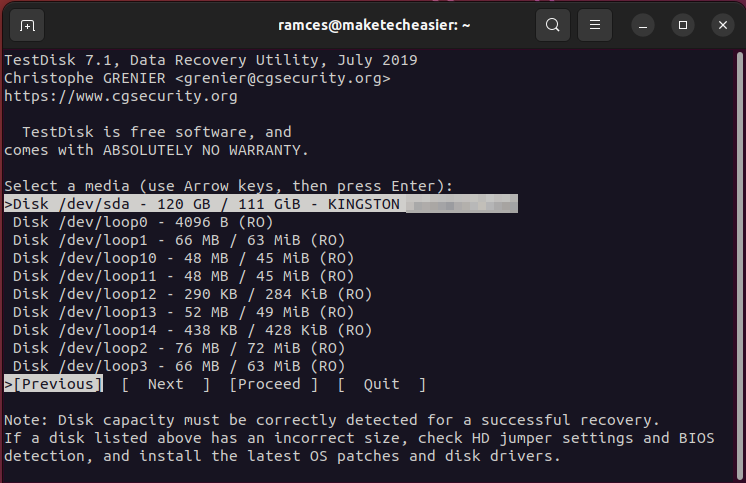
- Select the disk that you want to recover. In my case, it is “/dev/sda.”
- Select the partition table type for your disk.
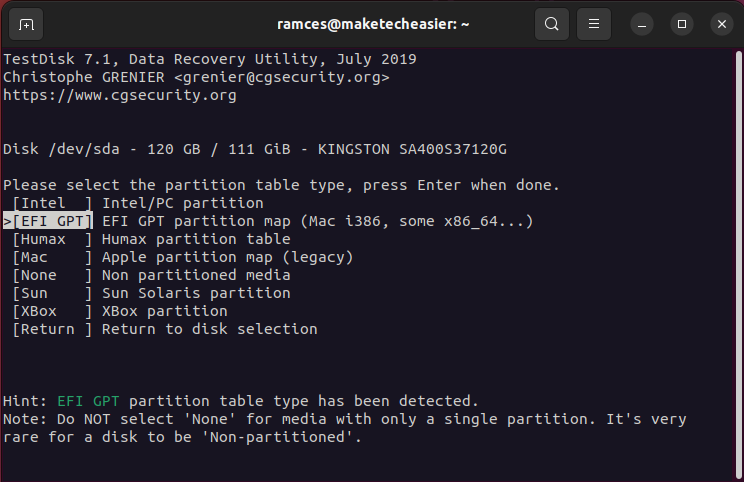
- Select “Analyze” to scan your disk for any inconsistencies with its current partition layout.
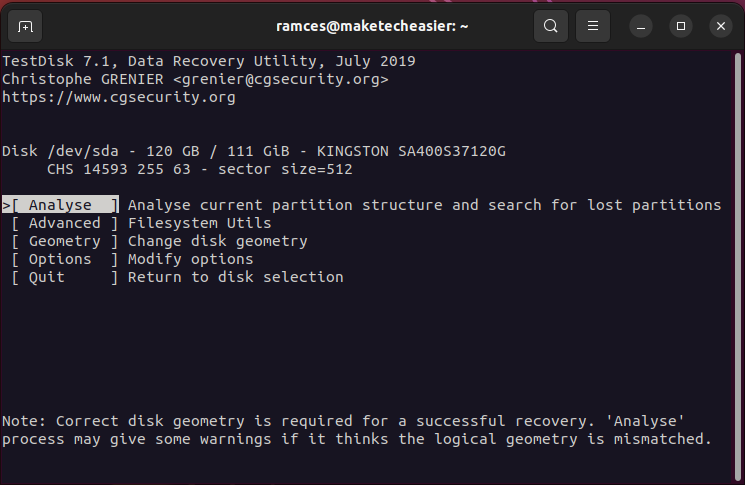
- Select the “Quick Search” option to start the partition retrieval process.
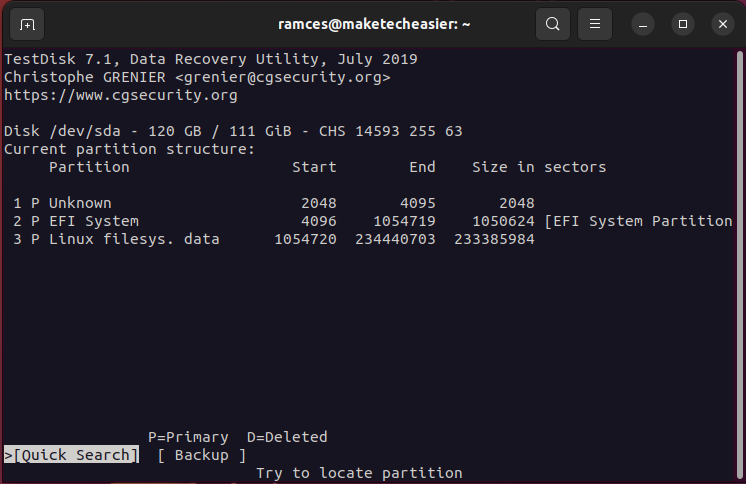
- Press Enter to accept Testdisk’s default values.
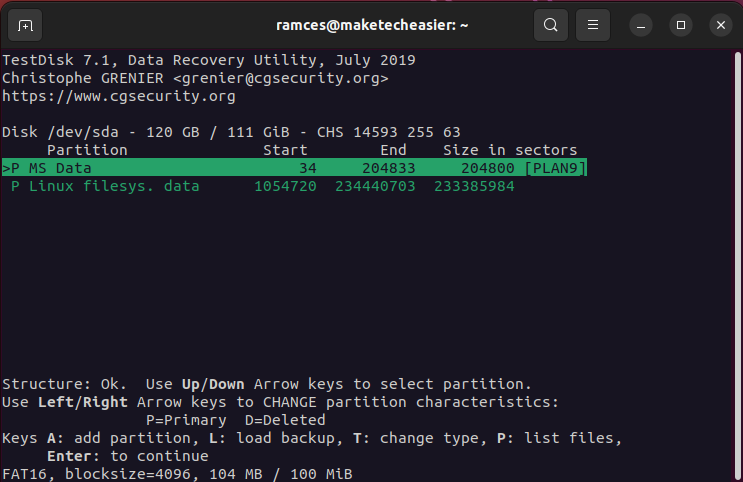
- Select “Write” to save your new partition layout.
Pros
- Restores entire disk partitions
- Fixes disks with an unbootable operating system
Cons
- Cannot restore individual files
- Restoring a partition will not guarantee that its contents will be there
2. Photorec
Photorec is a simple tool that can recover files through data carving in Linux. It’s a process where a program reads through a disk’s raw bytes to find the contents of a deleted file.
One of the biggest advantages of Photorec is that it is often bundled with the Testdisk package. You do not need to install any additional utilities and dependencies to start restoring files.
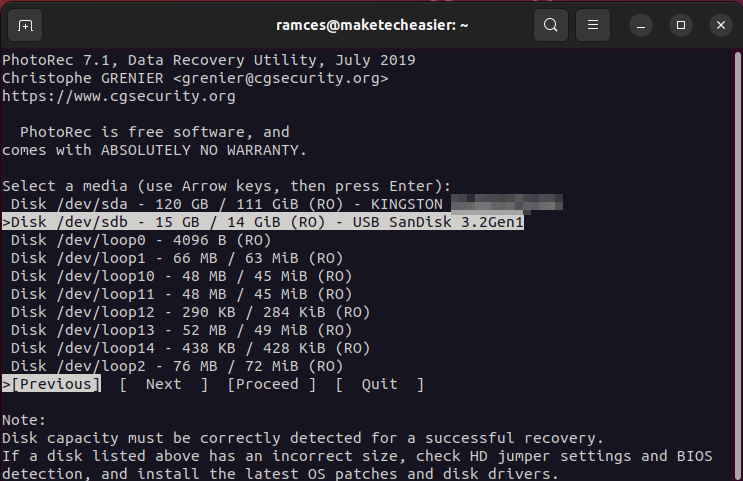
- Start restoring your data by running Photorec:
sudo photorec
- Highlight the disk that contains the files you would like to restore, then select “Proceed.”
- Select the “[Whole disk]” option, then press Enter.
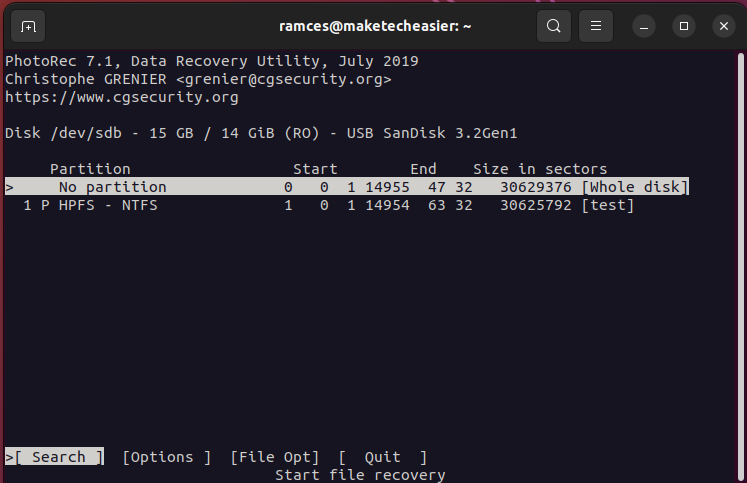
- Pick the filesystem that initially held your deleted file.
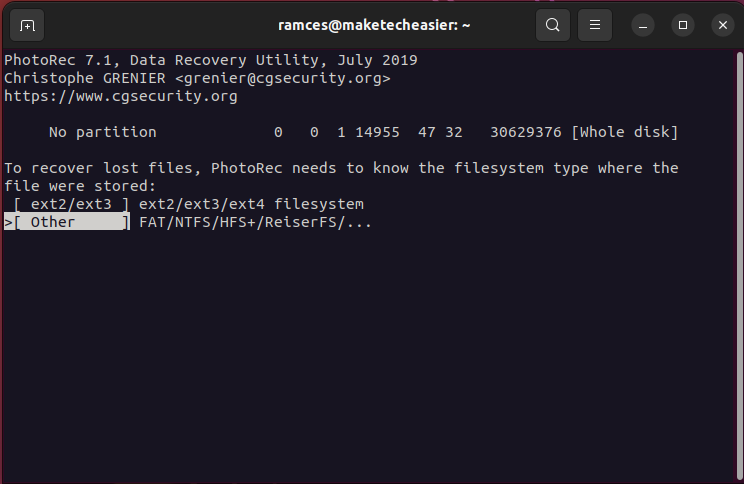
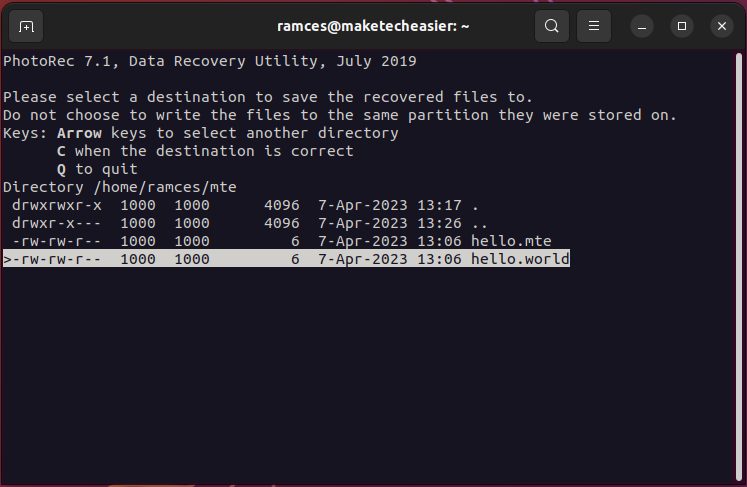
- Provide a “recovery directory” for Photorec. To select one, go inside your target directory using the arrow keys, then press C.
Pros
- Recovery algorithm is quick
- Handles a variety of filesystem formats
Cons
- Recovery can be punishing to solid state drives
- Requires a separate filesystem to store the files
3. Scalpel
Scalpel is a fast and efficient program that uses regular expressions to recover any lost files in a Linux disk. Similar to Photorec, Scalpel goes through your disk and looks for any byte pattern that could indicate the presence of existing data.
One advantage of Scalpel is that you can use regular expressions to fine tune what the program will recover, so it only takes a fraction of time compared to similar programs.
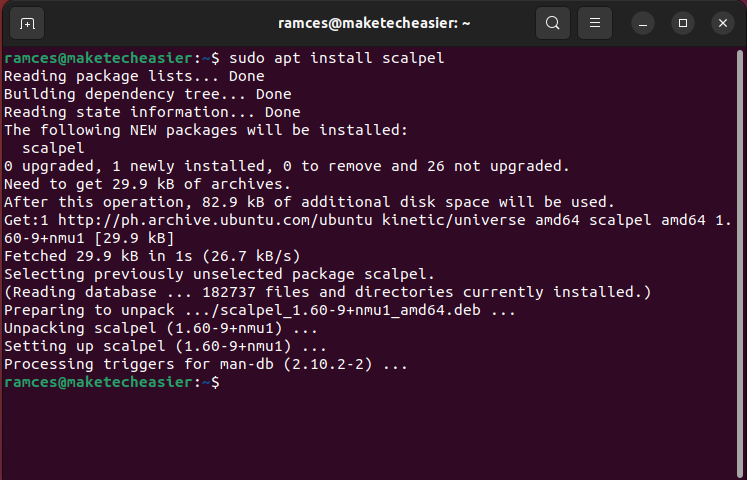
- Install Scalpel in Ubuntu and Debian by running the following command:
sudo apt install scalpel
- Copy Scalpel’s default configuration file to your home directory:
cp /etc/scalpel/scalpel.conf /home/$USER/
- Open the scalpel.conf file through your text editor:
nano /home/$USER/scalpel.conf
- Uncomment the lines with the file extensions you want to recover.
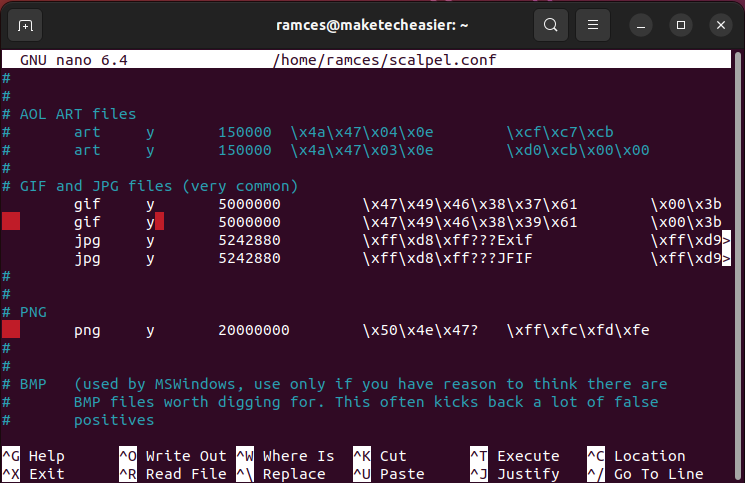
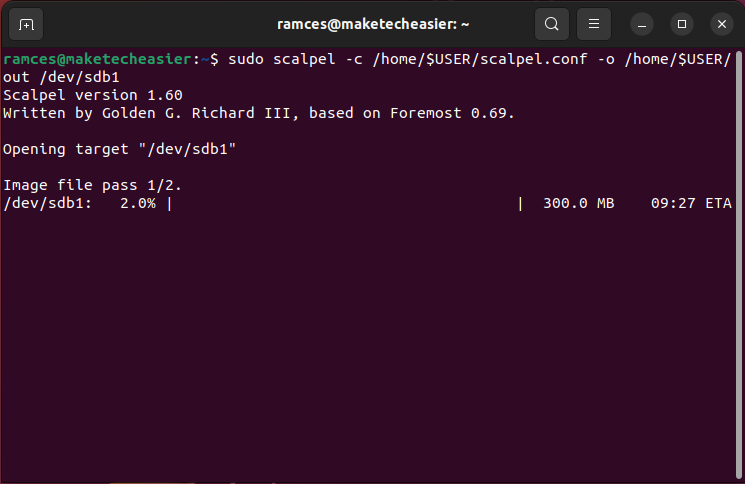
- Run Scalpel using the following command:
sudo scalpel -c /home/$USER/scalpel.conf -o /home/$USER/out /dev/sdb1
Pros
- Runs on both device files and disk images
- Allows you to filter the file type that you want to recover
Cons
- Configuration file can be confusing
- Can be unreliable at detecting file types
FYI: Scalpel originally started as a fork of the popular Foremost utility. Learn how you can use the original Foremost program to restore files in Linux.
4. ddrescue
ddrescue is a powerful data restoration utility that uses clever algorithms to preserve the contents of entire disk devices. Unlike a data carver, the primary goal of ddrescue is to recover and preserve data as accurately as possible.
By design, ddrescue does not extract files from a disk file with this approach. Rather, it creates a “snapshot” of the current state of a disk, which can be helpful in cases where you are extracting data from an intermittent, failing hard drive.
- You can install ddrescue in Ubuntu and Debian by running the following command:
sudo apt install gddrescue
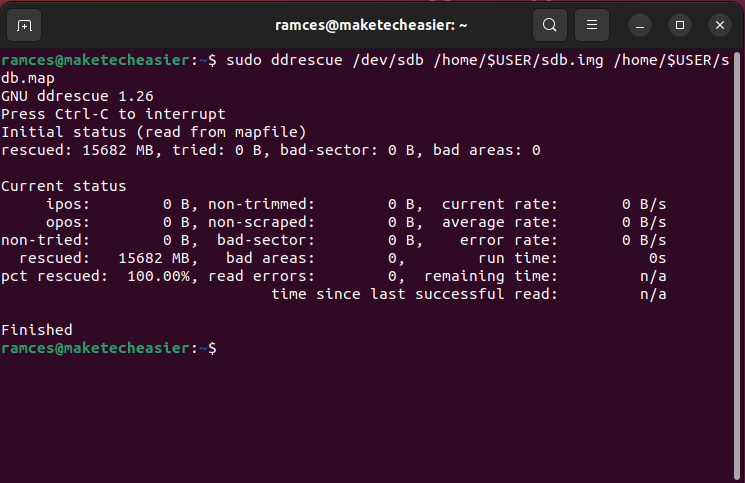
- Start preserving your disk’s contents. For example, the following command will create an image file out of the “/dev/sdb” disk device:
sudo ddrescue /dev/sdb /home/$USER/sdb.img /home/$USER/sdb.map
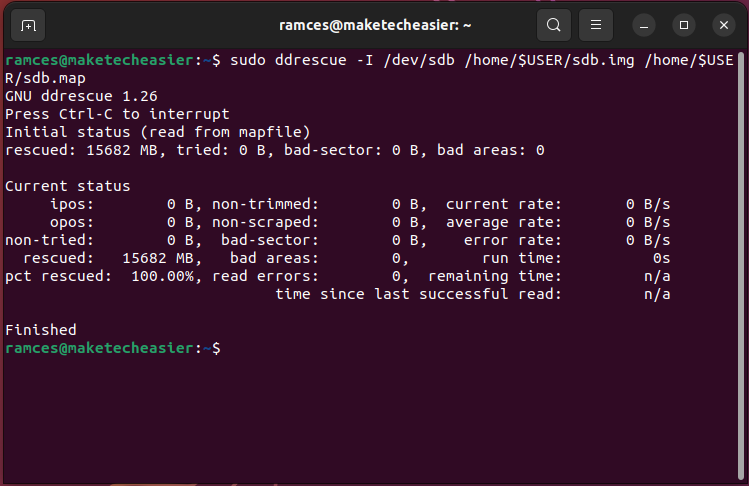
- Verify the integrity of your snapshot by using the
-Iflag:
sudo ddrescue -I /dev/sdb /home/$USER/sdb.img /home/$USER/sdb.map
Pros
- Creates an accurate duplicate of your disk
- Skips around bad sectors on a hard drive
Cons
- Will not directly recover a missing file
- Can be slow on large hard disks
5. Fatcat
Fatcat is a lightweight program that can recover files inside FAT-type filesystems in Linux. This includes the old FAT12 format up to the more recent FAT32. Fatcat can be a great tool for restoring data from old hard disks.
One of the best features of Fatcat is that it can be a portable file explorer for FAT-type disks. You do not need to extract an image file to access and restore its contents.
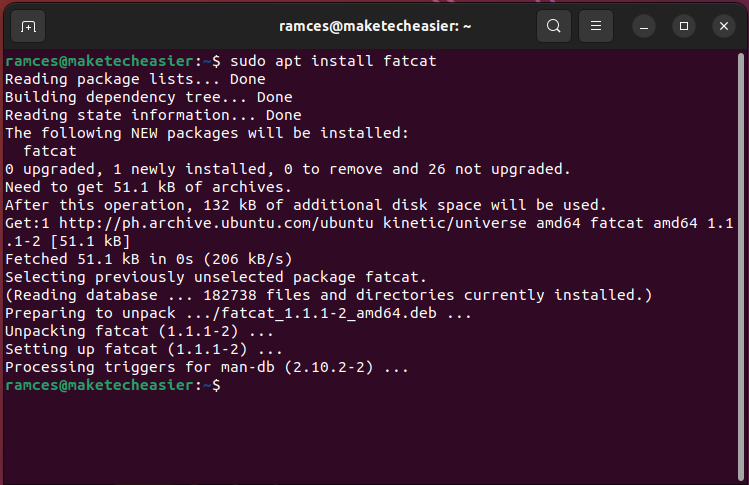
- Install Fatcat in Ubuntu and Debian by running the following command:
sudo apt install fatcat
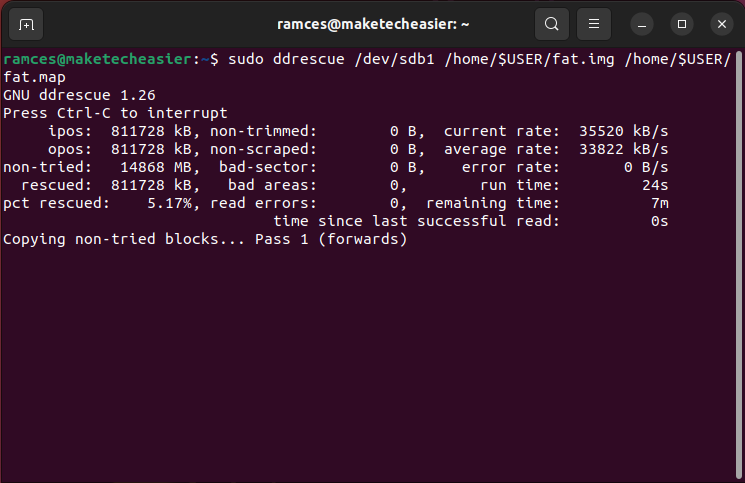
- Create an image file of your FAT partition using ddrescue:
sudo ddrescue /dev/sdb1 /home/$USER/fat.img /home/$USER/fat.map
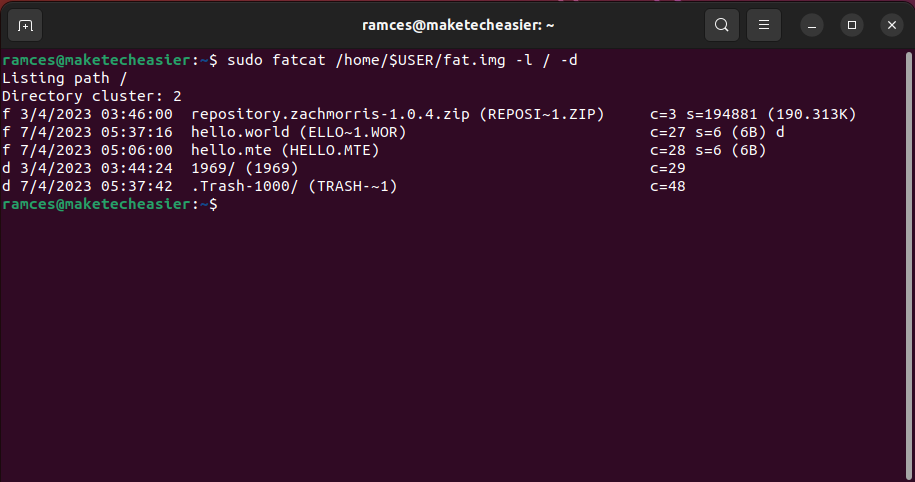
- Verify the contents of your FAT image by listing its root:
sudo fatcat /home/$USER/fat.img -l / -d
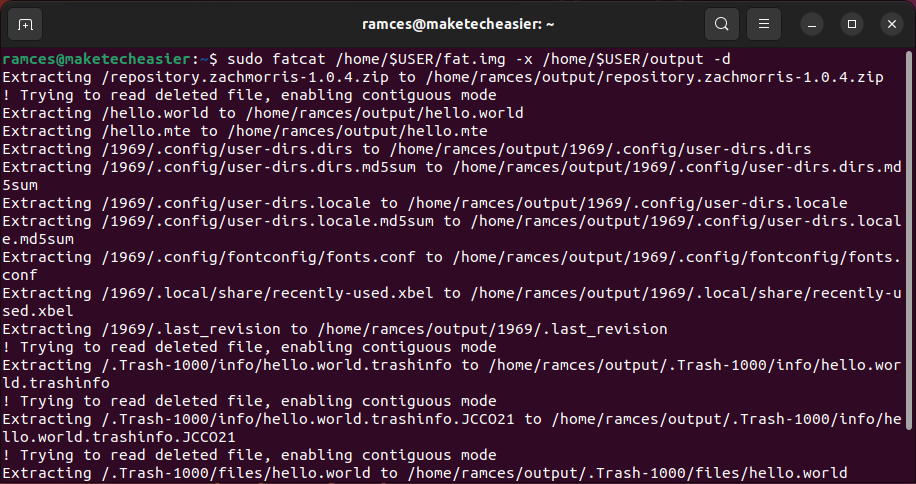
- Dump the contents of the FAT partition in your own filesystem:
sudo fatcat /home/$USER/fat.img -x /home/$USER/output -d
Pros
- Loads the contents of a FAT partition on the fly
- Fixes broken FAT filesystems
Cons
- Does not support exFAT
- Restoring individual directories can be tricky
6. Ntfsundelete
Ntfsundelete is a utility that can repair and recover files in NTFS filesystems on Linux. Similar to Fatcat, Ntfsundelete can recover individual files as well as entire directories and disks.
Ntfsundelete is on most Linux distributions by default, as it is included in the ntfs-3g package that serves as a compatibility layer for NTFS on Linux.
- Create an image file of your NTFS partition using ddrescue:
sudo ddrescue /dev/sdb1 /home/$USER/ntfs.img /home/$USER/ntfs.map
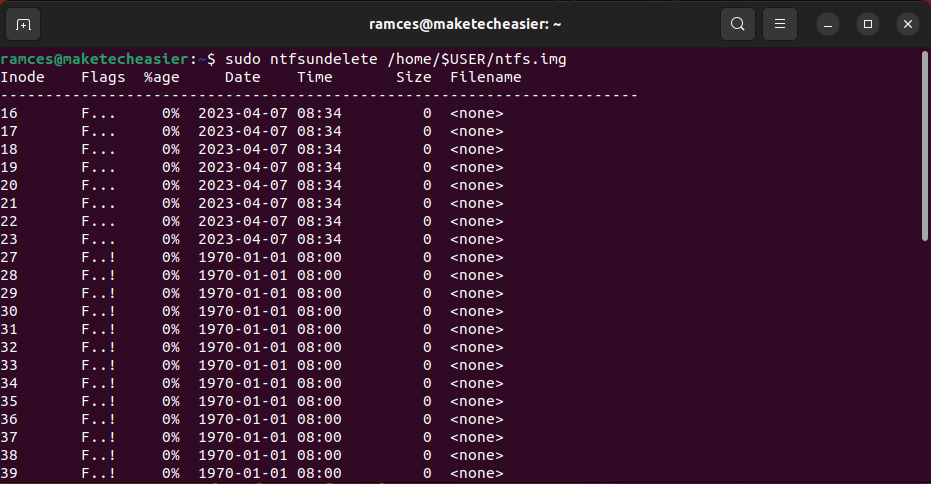
- Test the consistency of your image file by listing its contents:
sudo ntfsundelete /home/$USER/ntfs.img
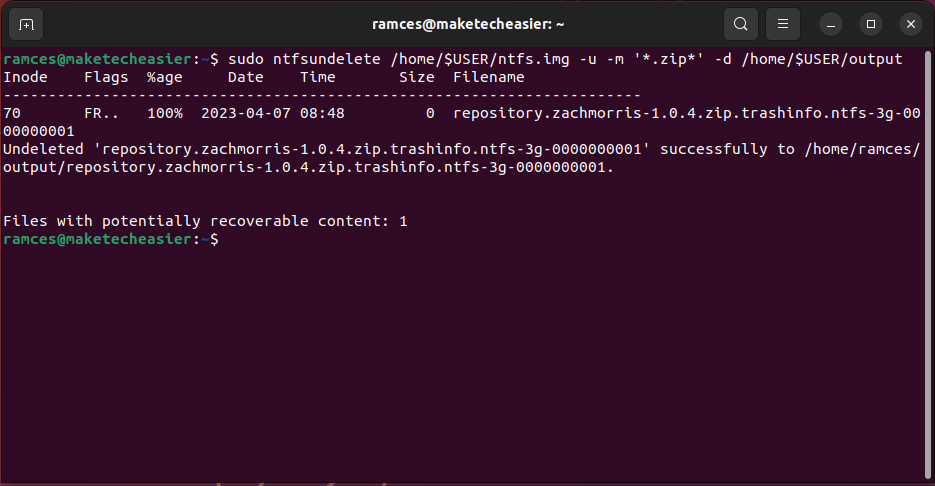
- Recover data from your disk image. For example, the following command will restore all the ZIP files from the disk image:
sudo ntfsundelete /home/$USER/ntfs.img -u -m '*.zip*' -d /home/$USER/output
Pros
- Core part of most Linux distributions
- Restores individual files
Cons
- Unreliable with device files
- Restored filenames may differ from the original
7. Ext4magic
Aside from restoring files inside FAT and NTFS partitions, it is also possible to recover files from Linux’s Ext filesystem. Ext4magic is a powerful program that can undelete almost any file from either an Ext3 or Ext4 filesystem.
One of the selling points of Ext4magic is that it can recover files using date ranges. This can be useful in cases where you cannot remember the exact file name and type of your original file.
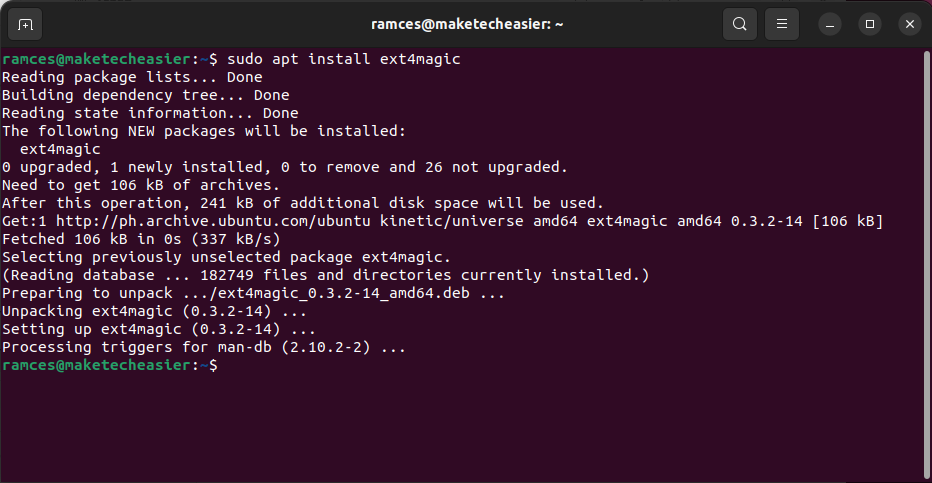
- Install Ext4magic in Ubuntu and Debian by running the following command:
sudo apt install ext4magic
- Create a partition image of your disk using ddrescue:
sudo ddrescue /dev/sdb1 /home/$USER/ext.img /home/$USER/ext.map
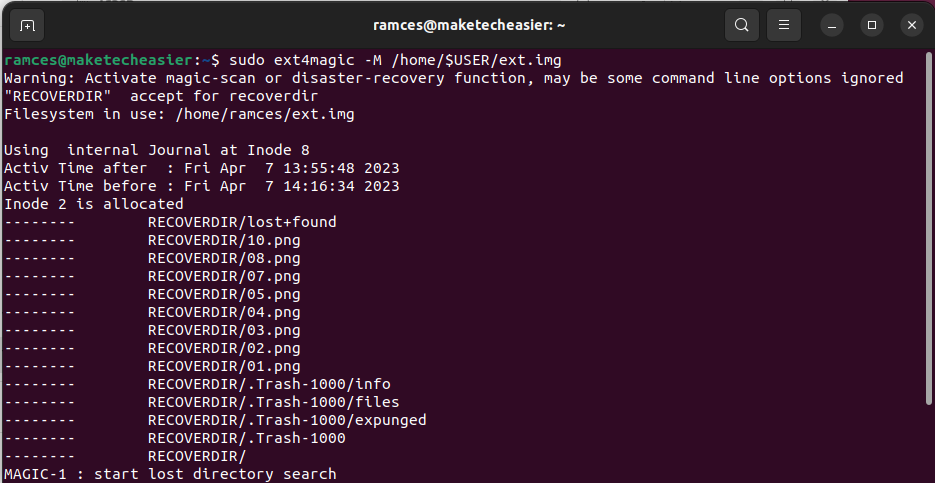
- Restore your deleted files using ext4magic. For example, the following command will restore all the files in my Ext4 disk:
sudo ext4magic -M /home/$USER/ext.img
Pros
- Uses a journal file to aid in restoring files
- Scans the filesystem for issues
Cons
- Date range option uses the UNIX epoch format
- Can be unreliable with older deleted files
Good to know: while recovery tools are effective at restoring files, it is still good practice to maintain a backup. Learn how you can create a secure cloud backup with Rclone.
Frequently Asked Questions
What can I do if Photorec is still unable to find my file after scanning?
In some cases, Photorec’s first recovery pass can miss some important byte data. To fix this, select the “Deeper Search” option after the first pass to tell Photorec to do a rescan.
Is it okay to enable all file extension filters in Scalpel?
Yes. However, it will reduce the effectiveness of Scalpel, as some of the file format entries in “scalpel.conf” can produce many false positives. It is good practice to only enable the options that you need for a specific scan.
Why can I not open my FAT image file with Fatcat?
This is most likely because of a mismatch between the image file and the format that Fatcat expects. To fix this, run ddrescue on the partition that contains the FAT filesystem rather than the entire disk.
Image credit: Unsplash. All alterations and screenshots by Ramces Red.