
There are plenty of ways you can download resources from the web. Other than your browser, you can also use a tool like wget to download resources from the Web while you do something else. In this article, we show you how to download and use wget on Mac.
Also read: How to Use Wget to Download Websites to Your PC
What is wget (And What It’s Used For)?
For the unaware, wget is an open-source non-interactive command-line utility to help you download resources from a specified URL. Because it is non-interactive, wget can work in the background or before you even log in.
It’s a project by the GNU team, and it’s great if you have a poor Internet connection. This means it’s robust in otherwise non-optimal conditions.
Once you install wget, you’ll run commands and specify a destination for your files. We show you how to do this next.
How to Install wget on Mac
Before you install wget, you need a package manager. While wget doesn’t ship with macOS, you can download and install it using Homebrew – the best Mac package manager available.
1. Download and Install Homebrew
To install Homebrew, first open a Terminal window and execute the following command:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
This uses the curl command to download files that ship within the pre-installed Ruby installation on macOS.
Also read: How to Use cURL for Command Line Data Transfer and More
Once you press Enter to run the command, the installer will give you explicit details on what will happen.
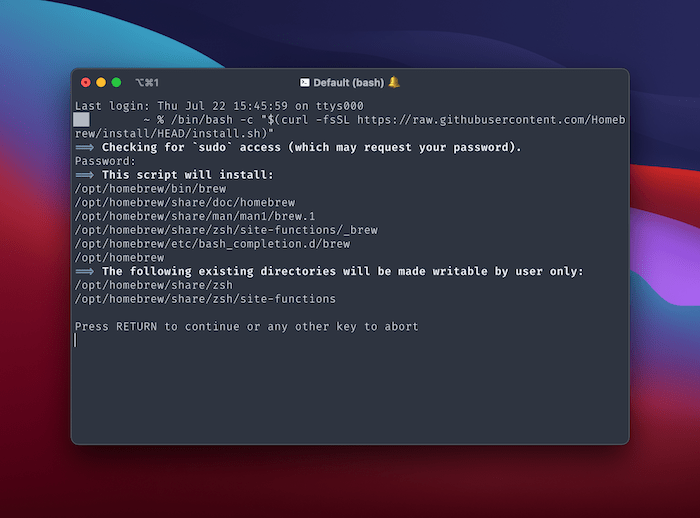
After you confirm, the installer will run.
2. Install wget From the Command Line
Next up, we want to use Homebrew to install wget. From the Terminal again, run:
brew install wget
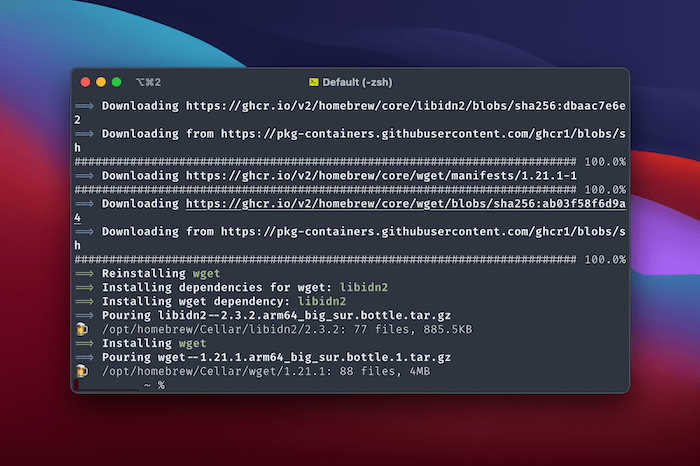
The installer will give you live progress updates, and there’s little you need to do here. The process is straightforward and automated. Though, if you already have Homebrew installed, be sure to run brew update to get the latest copies of all your formulae.
Once you see a new prompt within your Terminal, you’re ready to use wget on Mac to download resources.
Also read: How to Run a Python Script on Mac
How to Use wget to Download Web Resources
To download a remote resource from a URL using wget, you’ll want to use the following structure:
wget -O path/to/local.copy http://example.com/url/to/download.html
That will save the file specified in the URL to the location specified on your machine.
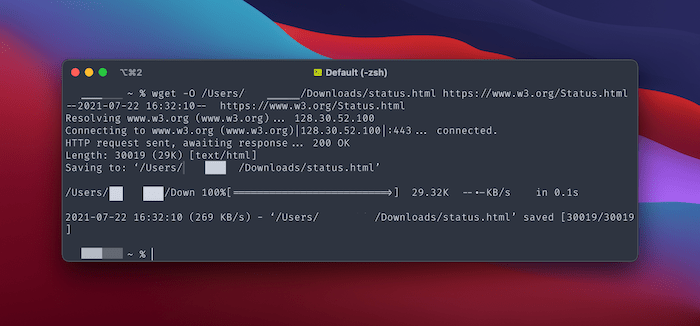
If you exclude the -O “flag,” your download location will the the current working directory.
For example, we want to download a webpage to the Downloads folder:
wget -O /Users/[your-username]/Downloads/status.html https://www.w3.org/Status.html
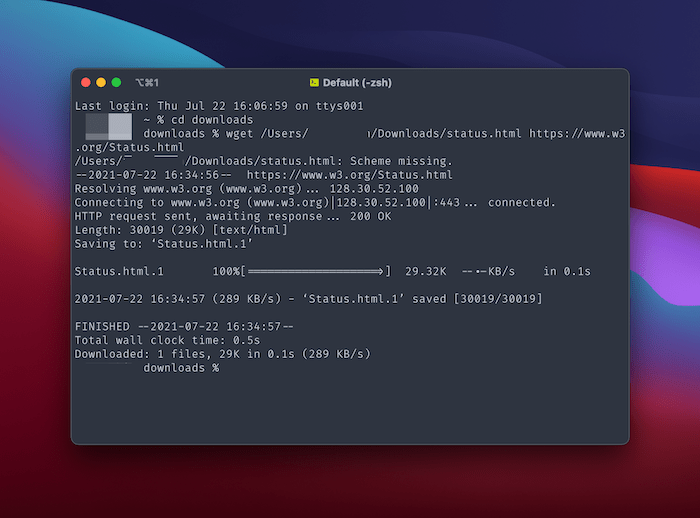
Though, to do the same without the -O flag, we’d need to change the directory (cd downloads) before we run wget:
wget /Users/[your-username]/Downloads/status.html https://www.w3.org/Status.html
You’ll get the full details on the download progress, although, with how quick wget is, this information is akin to a summary of the download rather than real-time updates.
How to Download a Recursive Directory
To download an entire directory tree with wget, you need to use the -r/--recursive and -np/--no-parent flags:
wget -e robots=off -r -np https://www.w3.org/History/19921103-hypertext/hypertext/
This will cause wget to follow any links found on the documents within the specified directory. From there it will perform a recursive download of the entire specified URL path.
Also, note the -e robots=off command. This ignores restrictions in the robots.txt file. In general, it’s a good idea to disable robots.txt to prevent abridged downloads.
Using Additional Flags with wget
You’ll find that wget is a flexible tool, as it uses a number of other additional flags. This is great if you have specific requirements for your download.
Let’s take a look at two areas in our focus on controlling the download process and creating logs.
Control How wget Will Download Resources
There are many flags to help you set up the download process. Here are just a few of the most useful:
wget -X /absolute/path/to/directorywill exclude a specific directory on the remote server.wget -nHremoves the “hostname” directories. In other words, it skips over the primary domain name. For example, wget would skip thewww.w3.orgfolder in the previous example and start with theHistorydirectory instead.wget --cut-dirs=#skips the specified number of directories down the URL before starting to download files. For example,-nH --cut-dirs=1would change the specified path of “ftp.xemacs.org/pub/xemacs/” into simply “/xemacs/” and reduce the number of empty parent directories in the local download.wget -R index.html/wget --reject index.htmlwill skip any files matching the specified file name. In this case, it will exclude all the index files. The asterisk (*) is a wildcard, such as “*.png”. This would skip all files with the PNG extension.wget -i filespecifies target URLs from an input file. This input file must be in HTML format, or you’ll need to use the--force-htmlflag to parse the HTML.wget -nc/wget --no-clobberwill not overwrite files that already exist in the destination.wget -c/wget --continuewill continue downloads of partially downloaded files.wget -t 10will try to download the resource up to 10 times before failing.
wget can do more than control the download process, as you can also create logs for future reference.
Adjust the Level of Logging
You can also consider the following flags as a partial way to control the output you receive when using wget.
wget -denables debugging output.wget -o path/to/log.txtenables logging output to the specified directory instead of displaying the log-in standard output.wget -qturns off all of wget’s output, including error messages.wget -vexplicitly enables wget’s default of verbose output.wget --no-verboseturns off log messag\es but displays error messages.
You would often want to know what’s happening during a download, so you may not use these flags as much as others. Still, if you have a big batch of downloads and want to make sure you can fix any issues, having a log or lack of output is a valid approach.
Also read: How to Add and Remove Kexts from macOS
Conclusion
While you could use your browser or another GUI to download web pages and other resources, you can save time with the command line. A tool such as wget is powerful – more so than your browser – and is snappy, too. For a full description of wget’s capabilities, you can review wget’s GNU man page.
If you find that wget isn’t working for you, it might be time to diagnose a problem with your Wi-Fi connection. Will you use wget on Mac to download web resources? Share your thoughts in the comments section below!







