Like most modern Linux distributions, Ubuntu comes with many tools by default for every need. Among them, you’ll find an Archive Manager with which you can store files in compressed packages. However, there’s a tiny problem: they might still be too large for what you need them to be. In such cases, your best bet is to compress and split the file into smaller parts.
Although Ubuntu comes with the tools to do precisely that, unfortunately, the Archive Manager isn’t the best for such tasks. That’s when you’ll have to turn to the terminal. Thankfully, the process is easy, and you can both compress and split your files in smaller chunks with a single command. Let’s see how.
Know Your Compression
Before we begin, we have to explain a little something about all forms of compression that will end up saving you precious time: it doesn’t stack up.
With that, we mean that if you have a bunch of highly-compressed files, you won’t gain much by recompressing them with a different type of compression. Suppose you want to share files like already highly-compressed JPG images, MP4 video files, or other compressed archives. In that case, there’s no point in using the highest compression settings available. It’s better to select to “store” them (without compression) in an archive.
For uncompressed or lightly-compressed files, though, like TXT files, large databases, or uncompressed media, going for the highest compression setting can produce radically smaller files.
The Classic Linux Approach
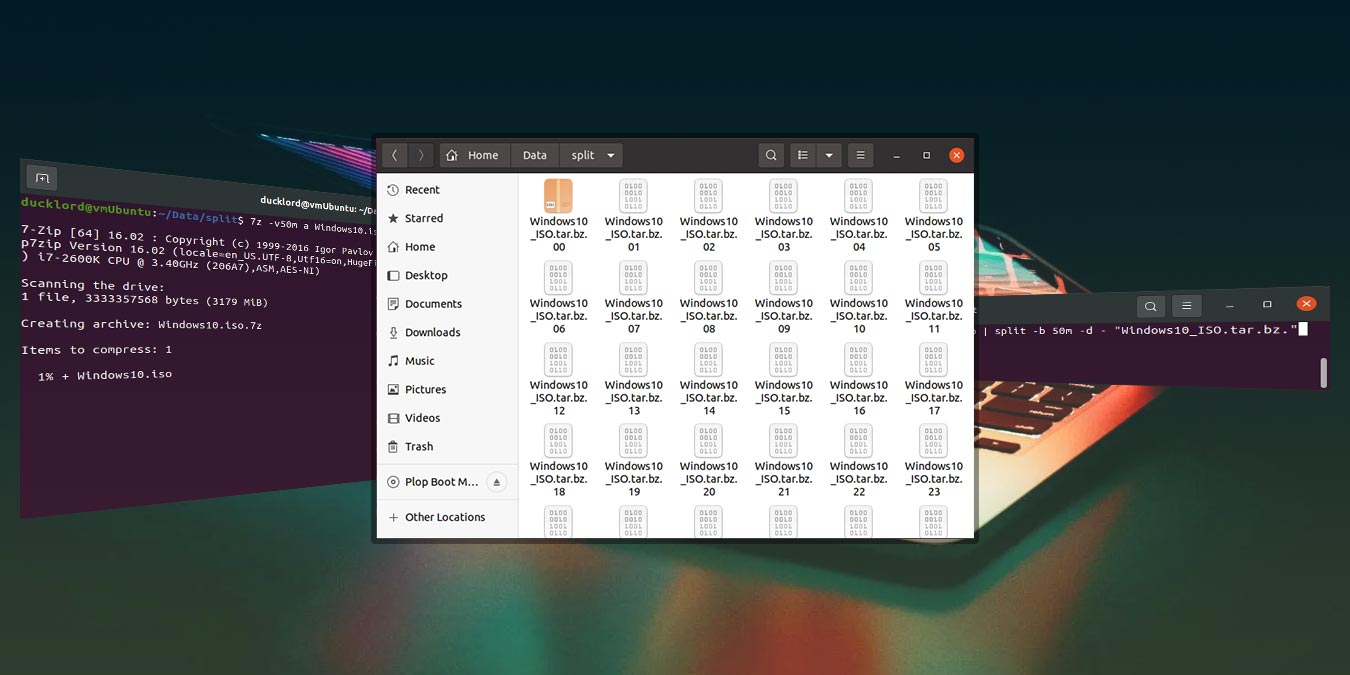
Let’s say you want to compress a file like the Windows 10 ISO used here. You can turn to the classic tools like tar, split, and bzip to compress and split it into smaller files.
1. Fire up your terminal. The quick way is by pressing CTRL + ALT + T. Then, move to the folder where you have the large file that you’d like to store in a split archive. To keep things clean, create a subfolder called “split,” where we’ll store the split archive, with:
mkdir split
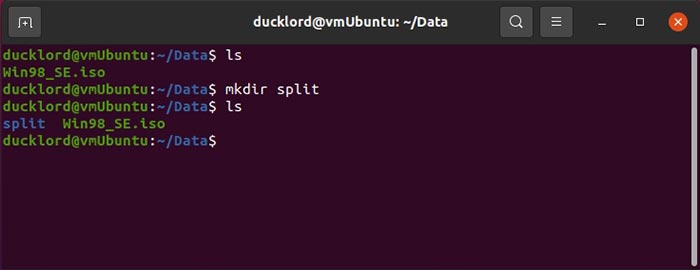
Then, enter it with:
cd split
- Use the following command to compress your file or folder into a split archive:
tar -cvj FILENAME | split -b SIZE_OF_PARTS -d - "BASE NAME OF ARCHIVE"
For our Windows 10 ISO, our command looked like:
tar -cvj ~/Data/Windows10.iso | split -b 50m -d - "Windows10_ISO.tar.bz."
- The “~/Data/Windows10.iso” is the path and filename of the file we wanted to compress.
split -b 50mstates that we want to split our archive into 50 MB parts. Change that value to reflect the size you’d prefer.Windows10_ISO.tar.bz.is the filename of the split archive files. Notice there’s an extra dot at its end. That’s because each chunk will also have a number at its end, reflective of its position in the sequence.

Soon after, depending on the size of the files you’re compressing and your computer’s speed, you’ll find the parts of your split archive in the split subfolder.
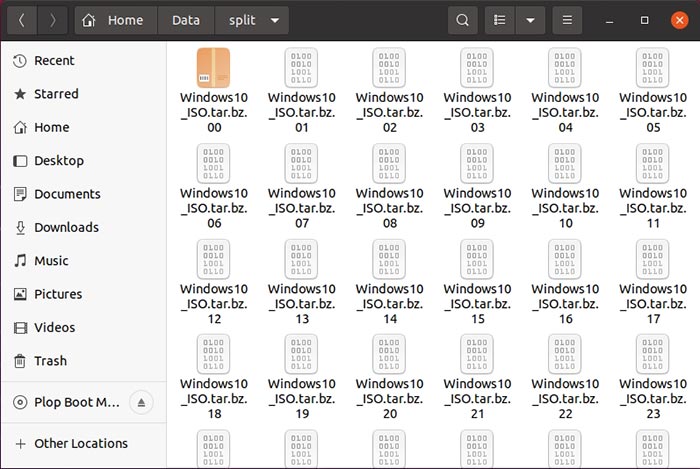
If you check their collective size, it will be smaller than their uncompressed total.
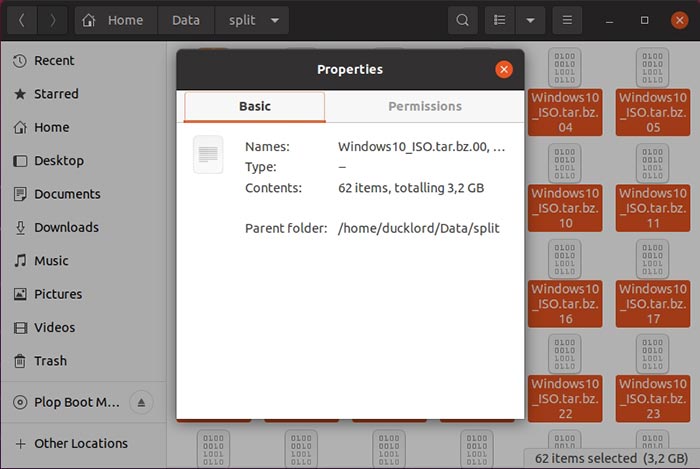
To get your original files back, you’ll first have to reassemble all the parts in a single archive with:
cat BASE_NAME_OF_PARTS.* > BASE_NAME_OF_PARTS.bz
Then, extract its contents with:
tar -xvj REASSEMBLED_ARCHIVE.bz
In our case, the two above commands would look like this:
cat Windows10_ISO.tar.bz.* tar -xvj Windows10_ISO.tar.bz
However, we can do better by using a newer compression tool, as you’ll see next.
The Modern High-Compression Solution
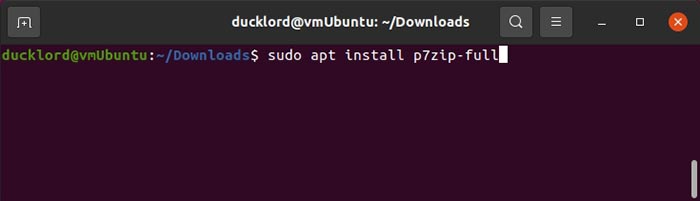
7Zip is a modern archiver that offers high compression rates and also comes with split archives support. Thus, it’s a better solution for the task at hand. However, Ubuntu doesn’t come with it. To install its Linux version, p7zip, use:
sudo apt install p7zip-full
Compressing your files in a split archive with it is even easier than the default solution we saw before. You only have to state the size of each split file, the base archive filename, and what you want to compress, with:
7z -vSIZE_OF_SPLIT_FILES a ARCHIVE_FILENAME FILE_TO_COMPRESS
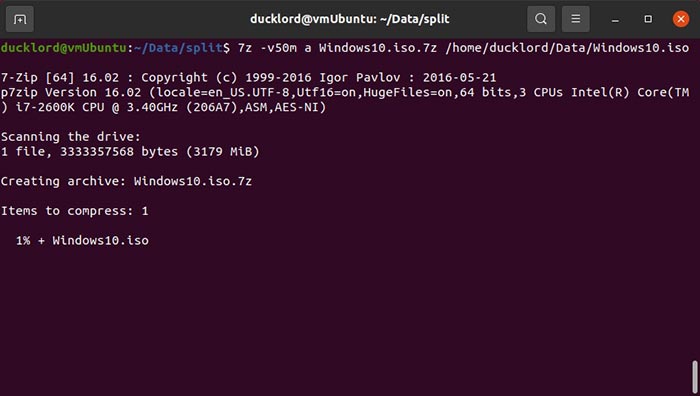
For our example of the Windows 10 ISO, to compress it in a multipart archive where each part would be 50 MBsin size, the command looks like:
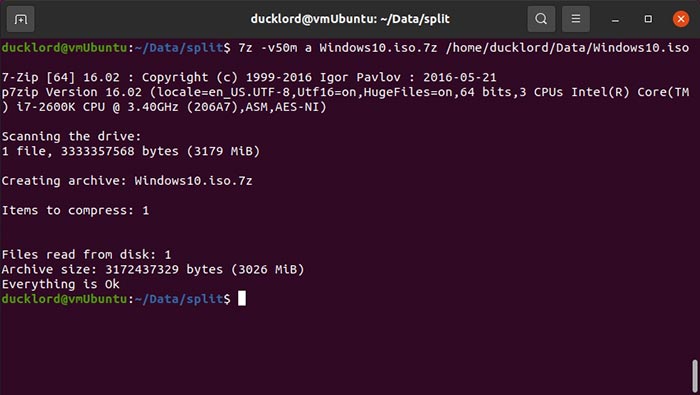
7z -v50m a Windows10_iso.7z ~/Data/Windows10.iso
After a while, you’ll find the results in the split subfolder, and they’ll take less size than if you used the tar-split-bzip approach we saw before.
To get your files back, extract only the first file of the sequence, and 7z will go through the rest automatically:
7z e FIRST_PART_OF_COMPRESSED_ARCHIVE
In our example, this was:
7z e Windows10_iso.7z.001
It’s also worth noting that, nowadays, you have many more options available for creating compressed archives with tools like pigz or plzip.
Do you find compressed split archives practical? Which compression tools are you using to deal with them? Tell us in the comments section below.