
While it often uses fairly complex algorithms, the goal of differential privacy is pretty simple: make sure that people whose data is collected have as much privacy as they would if the data had never been recorded. You should never be able to identify someone just by looking at a set of stored information about them.
Also read: I Have Nothing to Hide, So Why Should I Care About Privacy?
How Differential Privacy Works
Since data about us is being collected at an unprecedented rate and people are getting uncomfortable with it, the idea that your privacy can be mathematically proven is starting to look pretty good. Companies like Microsoft, Google, Apple, Facebook, and Uber have either implemented it in some form or are exploring their options, but even before big tech got interested, it was being used for things like sensitive research data, medical records, and even parts of the U.S. census.
It does this by adding noise, either to the stored data itself or to the results that get returned when someone queries it – messing up individual pieces of data but maintaining the overall shape. “Noise” is essentially irregularity, or unexplained variability, in data, and the goal here is to insert noise into individual data points while keeping overall measures like the mean, median, mode, and standard deviation close to where they were before.
Simple Differential Privacy
Let’s imagine that you’ve been selected to participate in a groundbreaking social science study. Here’s the catch, though: some of the questions are going to be potentially embarrassing, incriminating, or otherwise inconvenient for you. Let’s just say you’d prefer not having anyone see your name next to a checkmark in the column labeled “Actually liked the last season of Game of Thrones.”
Luckily, the researchers have anonymized the study. Instead of names, you get a random number, but even then, people can use your responses and narrow it down to you.
That’s a problem that’s actually come up quite a bit in the real world, perhaps most famously when researchers were able to not only identify Netflix users but even find out about some of their political preferences. But what if we could rig that data, as well as our survey, so that no one reading the results could know for sure what each person said?
Adding noise with coin flips
Here’s a technique we can use to both maintain your privacy and get results that, in aggregate, look like they would if everyone told the truth:
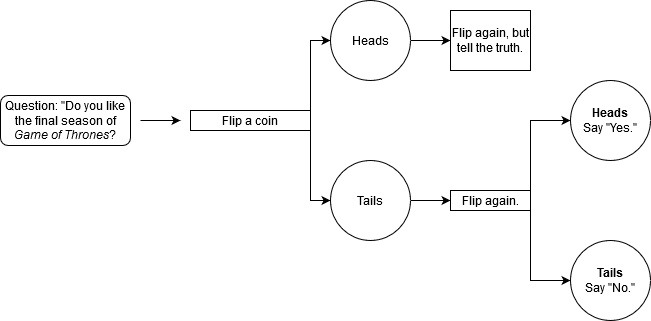
- We’ll ask you a yes/no question (Did you like the last Game of Thrones season?). You flip a coin.
- If the coin is heads, flip the coin again. (It doesn’t matter what you get the second time.) Answer the question honestly. (“Yes.”)
- If it’s tails, flip the coin again. If it’s heads, say “Yes.” If it’s tails, say “No.”
We won’t be looking at the coin, so we won’t know whether or not it told you to lie. All we know is that you had a 50% chance of telling the truth and a 50% chance of saying “Yes” or “No.”
Your answer is then recorded next to your name or ID number, but you now have plausible deniability. If someone accuses you of enjoying that last Game of Thrones season, you have a defense that is backed by the laws of probability: the coin flip made you say it.
The actual algorithms most tech companies are using for differential privacy are much more complex than this (two examples below), but the principle is the same. By making it unclear whether or not each response is actually valid, or even changing responses randomly, these algorithms can ensure that no matter how many queries someone sends to the database, they won’t be able to concretely identify anyone.
Not all databases treat this the same way, though. Some only apply the algorithms when the data is queried, meaning the data itself is still being stored in its original form somewhere. This obviously isn’t the ideal privacy scenario, but having differential privacy applied at any point is better than just pushing raw data out into the world.
How is it being used?
Apple
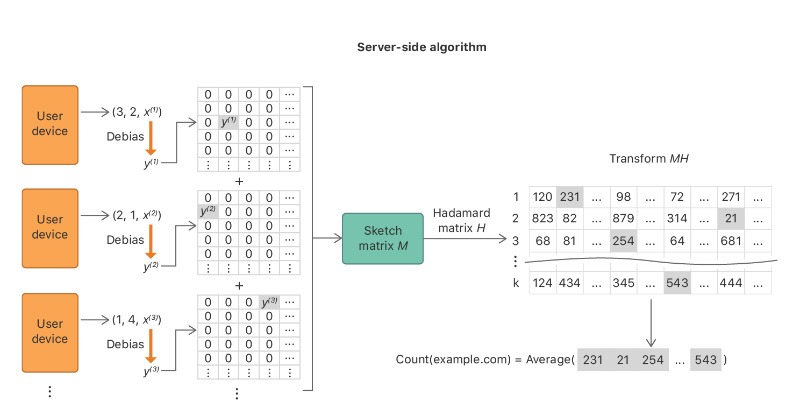
Apple uses differential privacy to mask individual user data before it’s ever submitted to them, using the logic that if a lot of people submit their data, the noise won’t have a significant impact on the aggregate data. They use a technique called “Count Mean Sketch,” which essentially means the information is encoded, random pieces are changed, and then the “inaccurate” version is decoded and sent to Apple for analysis. It informs things like their typing suggestions, lookup hints, and even the emojis that pop up when you type a word.
Also read: Apple Adds Privacy with “Sign in with Apple,” But Will Users Trust It?
Google’s first big foray into differential privacy was RAPPOR (Randomized Aggregatable Privacy-Preserving Ordinal Response), which runs the data through a filter and randomly changes pieces of it using a version of the coin-flip method described above. They initially used it to gather data on security issues in the Chrome browser and have since applied differential privacy elsewhere, like finding how busy a business is at any given time without revealing individual users’ activity. They’ve actually open-sourced this project, so there may be more applications popping up based on their work.
Why isn’t all data being treated this way?
Differential privacy is currently a bit complex to implement and it comes with an accuracy tradeoff that can negatively impact critical data in some circumstances. A machine-learning algorithm using privatized data for sensitive medical research might make mistakes big enough to kill people, for example. Nonetheless, it’s already seeing real use in the tech world, and given increasing public awareness of data privacy, there’s a good chance that we’ll see mathematically-provable privacy being touted as a selling point in the future.
Image credits: RAPPOR data flow, Server-Side Algorithm for Hademard Mean Count Sketch, Dataset-survey R-MASS package, Tree of probabilities – flipping a coin







