Traditional hard disk drives (HDDs) have all but gone out of fashion in favor of significantly faster and affordable solid state drives (SSDs). An SSD can easily boost your system’s responsiveness, especially if you’re running Windows on it. If you’ve recently bought a new SSD and want to migrate your Windows 10 installation to your SSD, this guide will provide you with everything you need to clone Windows 10 to an SSD.
Tip: not sure which disk cloning tool to use? Here are the best tools to clone Windows to an SSD.
What You Need to Clone Windows 10 to an SSD
Before we get started with the cloning process, you need to have a few things ready.
1. An SSD with enough space: If you’re only cloning your Windows partition to the SSD, you can get away with a 250GB SSD. But, if you want to clone multiple partitions or your entire HDD, then you need an equivalent or larger SSD.
2. A SATA/NVMe to USB adapter (optional): If you’re on a laptop that can only house a single drive, you’ll need an adapter to connect your SSD to the laptop using a USB port. This can be a SATA to USB cable or an NVMe to USB adapter. On a PC with available M.2 or SATA ports, you can simply install your SSD on the motherboard.

3. A screwdriver (optional): In case you need to install an M.2 drive on the motherboard of your PC or laptop, you’ll need a screwdriver. Motherboards with tool-less installation won’t require a screwdriver.
4. Disk cloning software: I prefer Macrium Reflect Home Edition to clone Windows as well as create data backups. It offers a 30-day free trial, so you have all the time to clone Windows to your SSD and try out its other features.
How to Clone Windows 10 to an SSD
Today’s NVMe SSDs can leave conventional HDDs and even SATA SSDs in the dust when it comes to read/write speeds. If you’re on the fence about which SSD deserves your money, you can pick one of our best solid state drives. If you’re curious about the various specifications and intricacies of SSDs, our SSD buying guide dissected everything you need to know.
With that out of the way, let’s get into the process of cloning Windows 10 to an SSD.
1. Back Up Your Data
The first thing you should do is back up your data on your current HDD or SSD. Cloning drives and partitions can sometimes encounter errors that might end up in you losing access to your data. Using File History to back up your data in Windows is one of the best ways to go about it.

Note: If you’re not using a new SSD, and have some data on the target disk, remember to back it up as well.
2. Ensure the SSD Is Detected
If you’ve installed or connected a new SSD to your PC or laptop, it might not be detected in Windows by default. The File Explorer will not show you the new SSD as a separate drive until you initialize it. You can do this quickly using Disk Management, which happens to be one of the best disk partition management tools for Windows.
Just search for “Disk Management” in the Windows search bar and click Create and format hard disk partitions. Disk Management will prompt you to initialize the drive before you can use it. Select either MBR (for legacy BIOS) or GPT (for UEFI firmware).
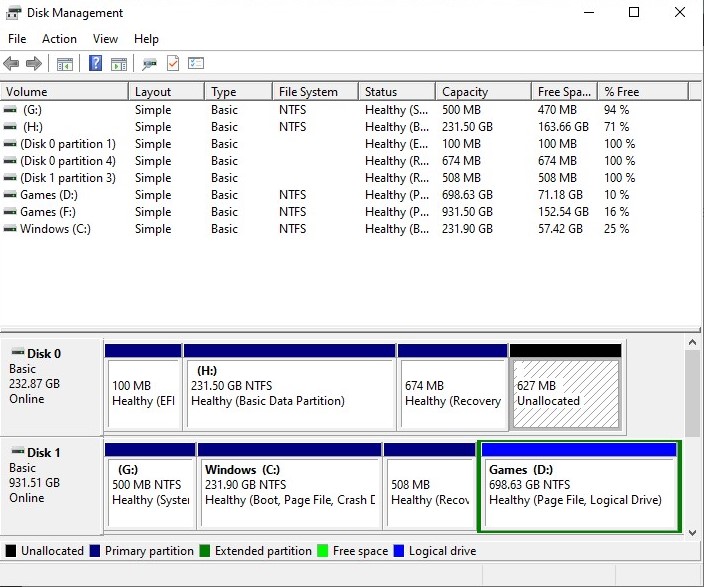
Once initialized, the drive will appear as Unallocated space in the bottom pane of the windows, alongside the other drives in your system.
3. Clone Your Drive With Macrium Reflect
Download the free trial for Macrium Reflect Home Edition by registering with your details. You’ll receive a registration code in your email that you need to enter during the installation process to register as a home user.
Once you’ve installed Macrium Reflect, restart your computer.
Launch Macrium Reflect as an administrator and click on the current drive that you want to clone to the new SSD. Click Clone this disk.
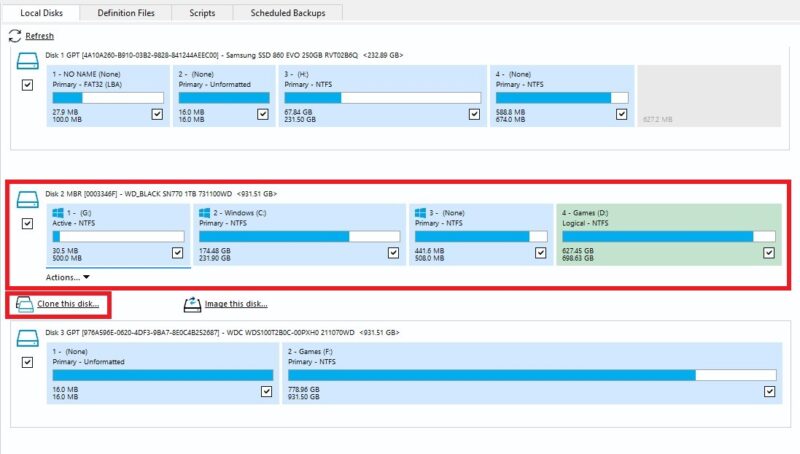
Click Select a disk to clone to and choose the new SSD as the target disk.
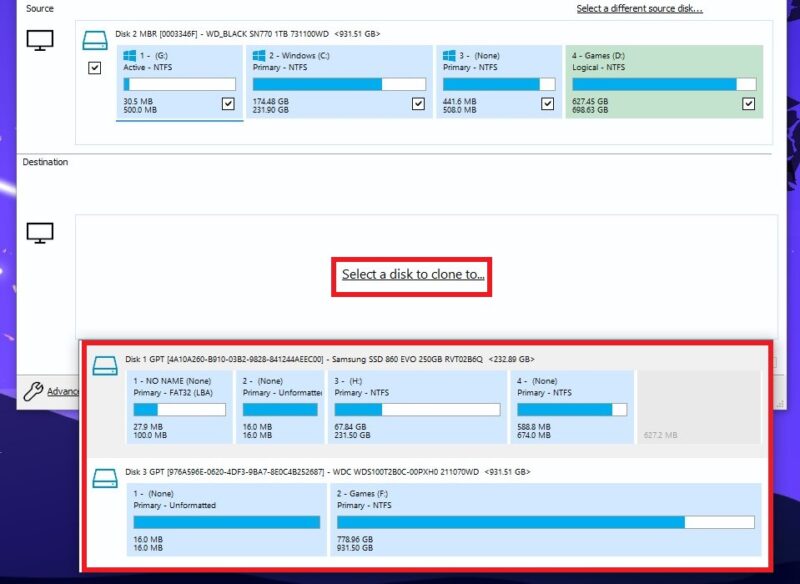
If the new SSD is smaller or larger than your current drive, you should select Copy Partitions -> Shrink or extend to fill the target disk. Alternatively, you can choose to clone only the Windows partition from the current drive by selecting the checkbox next to the respective partition and unchecking the ones next to the others. Click Finish.
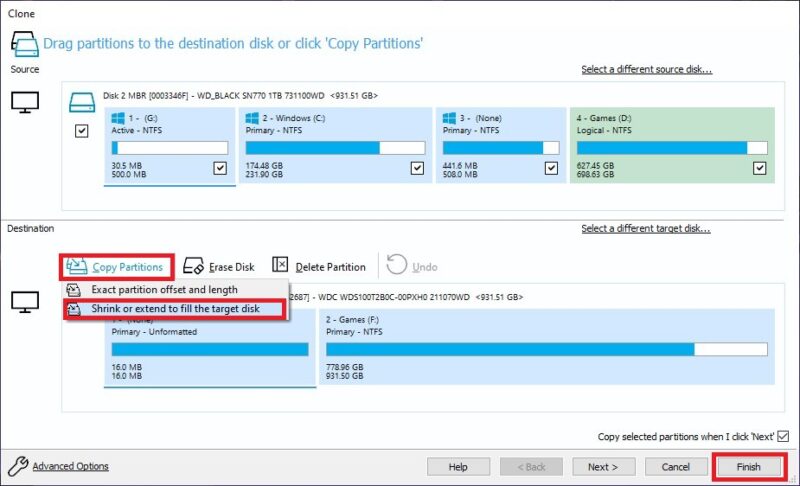
Click OK if prompted to create a backup definition file which you can run as a template in the future. Finally, click Continue on the Confirm Overwrite dialog box to confirm all data deletion on the target disk.
Click Finish once the process is complete.
FYI: fancy some Linux cloning? Here’s how to clone an entire hard drive on Linux.
4. Boot From Your SSD
Finally, you’re ready to boot from your new SSD. To ensure this step goes smoothly, you might have to enter your BIOS and select the SSD as the default boot drive. You’ll find the option somewhere in the boot options, as the exact location would differ from system to system.

In case you only have the SSD in your PC or laptop (having removed the previous drive), your system will automatically boot from the only boot drive it detects i.e. your SSD. For laptops with a single SATA or M.2 slot, you’ll have no option but to replace the previous drive with the new SSD.
If your PC has multiple storage slots, you can choose to retain your previous drive as secondary storage after wiping all data from it.
Good to know: need a bootable drive to install Windows? You can use Rufus to create a bootable USB drive.
Why Should I Clone Windows 10 to an SSD?
Cloning your Windows installation to an SSD can have immense benefits, extending even beyond speed and responsiveness.
- SSDs can bring a new life into older systems with slower HDDs.
- Migrating Windows 10 to an SSD can significantly speed up your boot time.
- Contrary to a fresh Windows install, cloning Windows 10 to an SSD saves you the time and hassle of reinstalling the OS as well as your applications. You’re essentially creating a replica of your existing Windows 10 installation on an SSD.
- Cloning is much more efficient than simply copying your files over to a new drive – you don’t run the risk of missing out on a few files or settings.
- For those upgrading to current-gen PCs and components, cloning Windows 10 becomes a necessity – a clunky HDD is out of place in a modern PC with fast and high-end components.
Tip: need the fastest SSD for your gaming PC? Here are the best SSDs for gaming.
Lift and Shift Windows 10 to an SSD
Cloning Windows 10 to an SSD is a seamless way to move your Windows partition or even your entire drive to a newer, faster drive. After all, the latest SSDs provide various benefits to your system, such as compatibility with DirectStorage in Windows 11, which is particularly helpful for gaming PCs. Even if you aren’t gaming on your PC, there are things that you must do when running an SSD in Windows.
All screenshots by Tanveer Singh.