Sed is a simple UNIX program that doesn’t create nor edit files. It only modifies the data that passes through its input and presents the modified data on its output. Here, we look at a brief overview of the UNIX philosophy, go through the basics of using sed, and show you examples of how to use the program for daily tasks.
The Basics of Using Sed
Sed is a program that can read and modify text data streams. This means that, unlike a regular text editor, sed doesn’t directly change files in your computer. Instead, it acts more of a “filter” for incoming data and allows you to transform it in however way you wish.
To get started with sed, first create a file with at least five lines of text inside it. Make sure that there’s a “new line” character in between your lines:
printf "hello\nmaketecheasier\nworld\nthis\nis\nwonderful\n" > hello.txt
Note: while this guide uses a multi-line text file to demonstrate sed, all of the subcommands in the program will also work on text that came in from UNIX pipes.
The general command for sed is something like:
sed [option] '{script}' [text file]
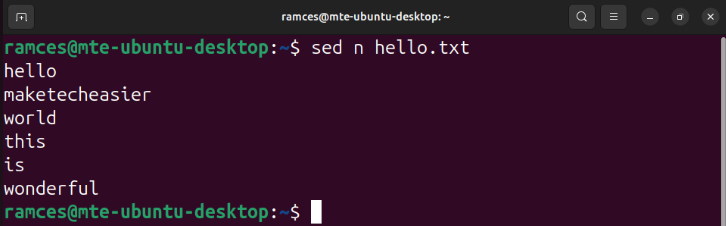
One of the most basic functions in sed is the n subcommand. It works by reading data from sed’s input and placing it in your program’s “pattern space.” This is a special buffer that holds any incoming text before sed does any manipulation to it:
sed n hello.txt
Another one of sed’s basic functions is the p subcommand. Similar to n, it reads the data coming in from sed’s input and places it in the program’s pattern space. However, it also explicitly prints it on your terminal’s output.
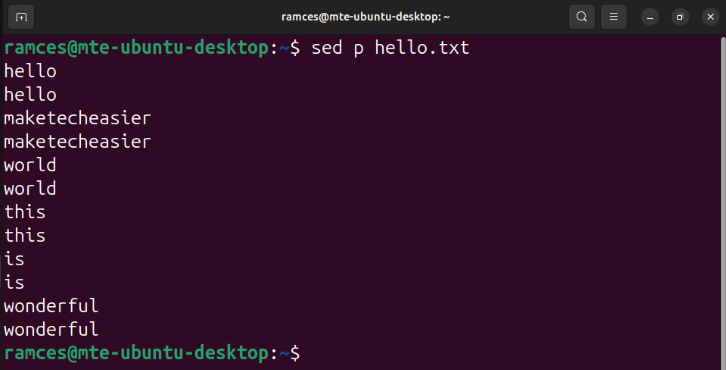
Using the p subcommand can be confusing for beginners since running it with any text input results in sed printing its output twice. This is because, by default, sed automatically prints its pattern space regardless if p is present or not:
sed p hello.txt
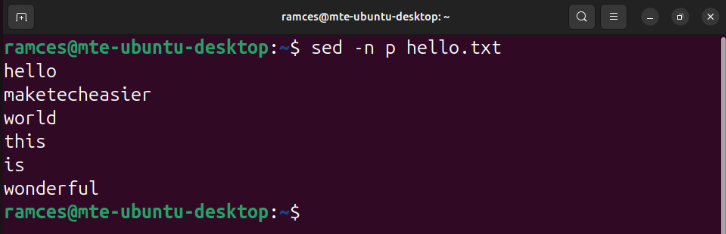
To disable this quirky behavior, add the -n flag before you run your sed subcommands:
sed -n p hello.txt
With the basics out of the way, the following sections will look at the different ways that you can use sed to manipulate text data.
1. Selecting and Trimming Text Streams
Aside from printing, you can also use sed to select and trim text from both data streams and files. The easiest way to do this is by adding a range value to the p subcommand.
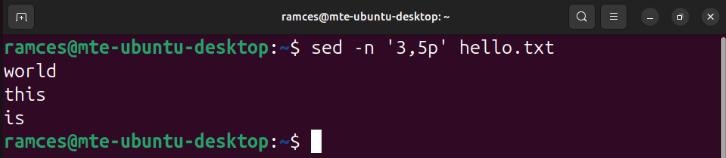
The following command uses sed’s range syntax to print the third to fifth line in your “hello.txt” file:
sed -n '3,5p' hello.txt
You can also use the p subcommand to print non-adjacent lines in your text. For instance, the following prints the first and fourth line in the “hello.txt” file:
sed -n '1p; 4p' hello.txt

2. Removing Text from a Sed Stream
Sed can also delete data from any incoming text stream. This is helpful if you want to either remove a few lines of text from a large file or clean up a program’s output to only show the information that you need.
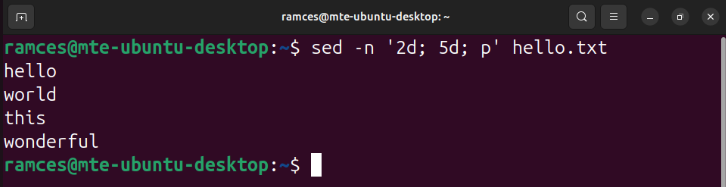
To do this, use the d subcommand along with the specific line or range that you want to delete:
sed -n '2d; 5d; p' hello.txt
Similar to printing lines of text, the d subcommand works with multi-line ranges. For instance, the following command will delete the first four lines from the “hello.txt” file:
sed -n '1,4d; p' hello.txt

In addition to matching specific line ranges, you can use regular expressions to find the text that you want to delete. Doing this will tell sed to look for any lines that contain the word “world” and delete it:
sed -n '/world/ d; p' hello.txt
You can also treat regular expressions as a range for your input file. This gives you more flexibility in defining your selections within the program:
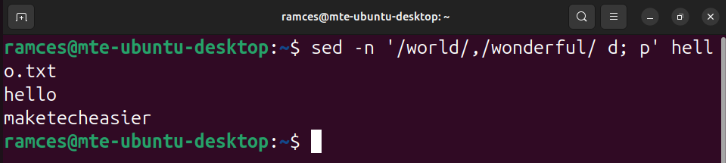
sed -n '/world/,/wonderful/ d; p' hello.txt
3. Adding New Text to a Sed Streams
On top of deleting text, sed is also capable of adding new text to existing data streams. While it’s not on the level of a full-blown text editor, this feature can still be handy for one-off edits and basic text additions.
To add a new line of text, run sed with the a command followed by the text that you want to add:
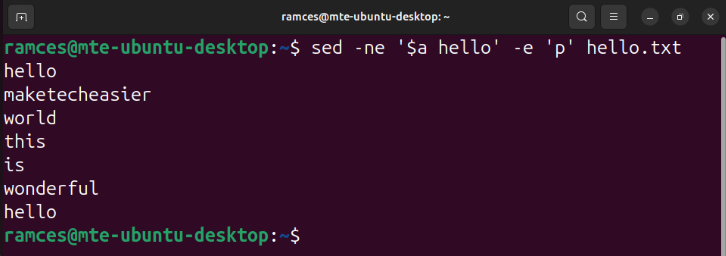
sed -ne '$a hello' -e 'p' hello.txt
Note: the -e flag tells sed that the quoted string after it is a sed expression. This allows you to chain multiple expressions together without invoking sed multiple times.
It’s also possible to include entire files into a sed text stream. To do that, use the r command followed by the name of the file that you want to add:
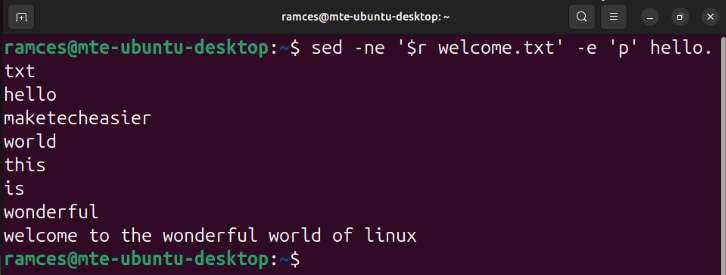
sed -ne '$r welcome.txt' -e 'p' hello.txt
4. Finding and Replacing Text in Sed
One of the most powerful features of sed is its ability to find and replace text from a text stream. Unlike adding and deleting text, this allows you to dynamically edit data as it passes through UNIX pipes making it a lot more flexible compared to a regular text editor.
Start by test printing your text input without any modifications from sed:
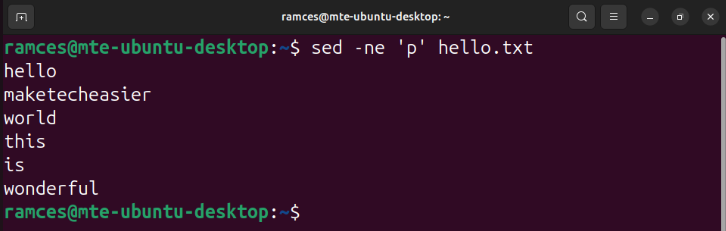
sed -ne 'p' hello.txt
Replace the p subcommand with s, then add three backslashes (/) after it:
sed -ne 's///' -e 'p' hello.txt
Insert a structural regular expression of the character string that you want to match in between the first and second backslashes. For example, I can put the following value to look for words that start with “wo” in my input string:
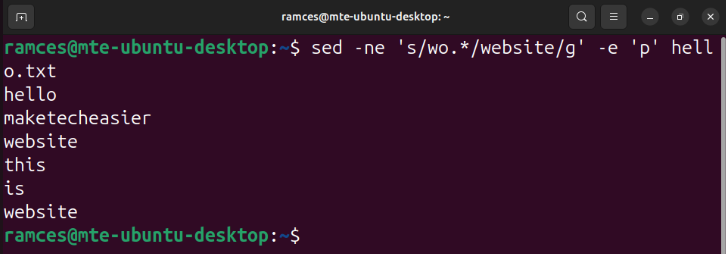
sed -ne 's/wo*.//' -e 'p' hello.txt
Place your text cursor in between the second and third backslashes, then provide the text that you want to replace your matches with. In contrast to the previous column, this section doesn’t use structural regular expressions:
sed -ne 's/wo.*/website/' -e 'p' hello.txt
By default, sed only replaces the first string that it matches on any particular line. This can be issue if you want to replace every instance of a word in your text stream. To fix this, add the g option after the third backslash of your expression:
sed -ne 's/wo.*/website/g' -e 'p' hello.txt
5. Copying Text Data to the Hold Space
Sed uses two buffers to store text data: the pattern space and the hold space. The former serves as a temporary place for your text as it goes through sed expressions. Meanwhile, the latter acts as a clipboard where you can store arbitrary text data.
One benefit of this approach is that it allows you to “hold on” to certain outputs without relying on external programs. This can be useful if you’re planning on using sed to process multi-step text manipulations.
To start using hold spaces, first make sure that you have a file with at least a few lines of text inside it:
sed -ne 'p' hello.txt
Replace the p subcommand with h, then provide either a line number or regex value that sed will match in your file. Doing this will tell sed to take that specific line of text and copy it to its hold space:
sed -ne '3h' hello.txt
Note: the data inside a hold space doesn’t persist across different sed commands.
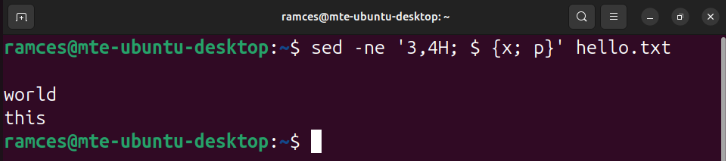
You can also use the H subcommand to store multiple lines of text inside your hold space. For example, the following command stores the third and fourth line of my text file and prints it back to the terminal:
sed -ne '3,4H; $ {x; p}' hello.txt
6. Using Labels to Create Loops in Sed
While sed is not a comprehensive programming language, it’s still possible to create loops inside the program. This is useful if you need a sed expression that has to continuously go over a particular piece of text input.
To create a loop in sed, you need to first make a label for your sed expression. For that, you need to use the : subcommand followed by the label that you want to use for your expression.
sed -e ':x' hello.txt
Provide the matching criteria for your sed expression. In my case, I want it to go to the end of every line in my input text:
sed -e ':x; $' hello.txt
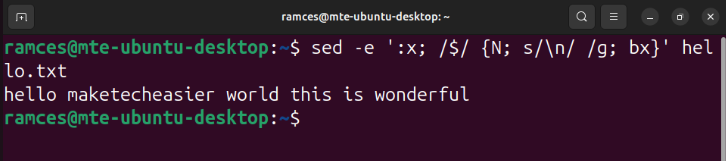
Type in the sed subcommands that you want to run whenever sed finds a match, then enclose it in curly braces. The following joins two adjacent lines, replaces the newline character with a space, then goes back to the start of the expression:
sed -e ':x; /$/ {N; s/\n/ /g; bx}' hello.txt
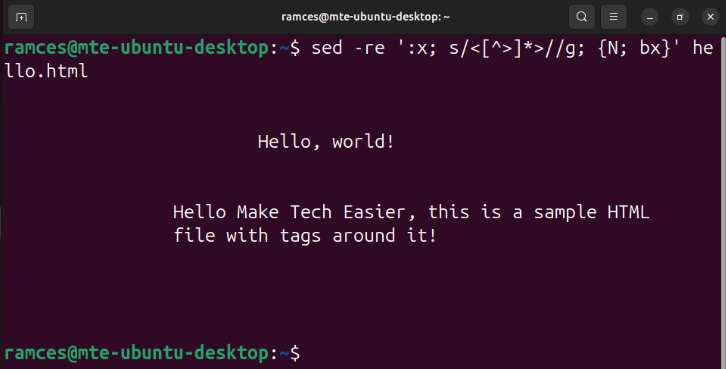
You can even extend this to match almost any kind of input text. For instance, the following command uses sed’s extended regex feature to strip HTML tags from your input text:
sed -re ':x; s/]*>//g; {N; bx}' hello.html
7. Making Permanent Changes in Sed
Just like with any other UNIX tool, sed can take advantage of output redirection and pipes. Not only does this allow you to glue together sed with other programs, but it also gives you the opportunity to make your changes permanent.
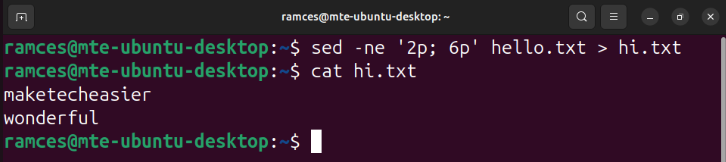
The following line of code creates a new “welcome.txt” file from the output of my sed command:
sed -ne '2p; 6p' hello.txt > hi.txt
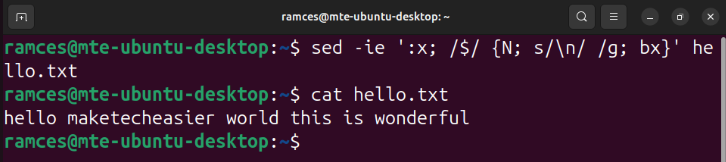
Aside from output redirection, you can also use the built-in -i flag to edit your current file instead of outputting your changes in your terminal console. For instance, the following command removes any newline characters from my text file and saves it:
sed -ie ':x; $; {N; s/\n/ /g; bx}' hello.txt
If all this talk made you curious with the Linux command line. You can read our earlier article where we talk about some of the most interesting Bash prompts that you can use today.
Image credit: Morgan Richardson via Unsplash. All alterations and screenshots by Ramces Red.