Git is a wonderful program. It is a version control utility that allows you to seamlessly manage a file’s edit history. While this might seem simple and unimpressive, Git’s strength lies in the fact that you can extend this history to entire groups of files and directories.
This means that it is possible to use Git to track every change in every file for every directory. This is highly useful if you are doing a project where you want to have a rolling snapshot of everything that you are doing.
Also read: How to Determine Whether a Website Is Legit and Safe to Use
What is Git?
At its core, Git is a simple history tracking program. In that, it tracks the changes across different versions of a file. The way it works is that whenever you change a file, Git will create a hash for that specific file version.
From there, it then compares and analyzes these hashes against the repository’s “Git tree”. Doing it this way then allows Git to only store the difference between multiple file versions.
For example, if you are writing a script under Git and you made a couple of changes to it. Git will only store the hash of the first two changes and hash the current file against the first two. That way, Git can reconstruct the older versions without storing multiple copies of the same file.
This approach also allows you to easily scale your files and directories to a larger project. Since Git stores all historical data as hashes, it only needs to operate in your local machine. As such, you can easily export your work to other people and import their contributions without the need for external management software.
Installing Git
Git is a very common package in Linux-based operating systems. Because of that, installing it is incredibly easy. In most cases, it is already preinstalled in your system. If you are using Debian or Ubuntu, you can use apt to install Git:
sudo apt install git
For Fedora or RHEL, use dnf:
sudo dnf install git-all
Meanwhile, if you are using Arch Linux, you can also install Git using pacman:
sudo pacman -S git
Using Git for a Local Project
Using Git in your local machine is very simple. The first thing that you need to do is to create a new Git repository. Its primary purpose is to serve as a container for all the Git objects that you will add for this project.
In the folder that you want to track, run the following commands:
cd my-project git init
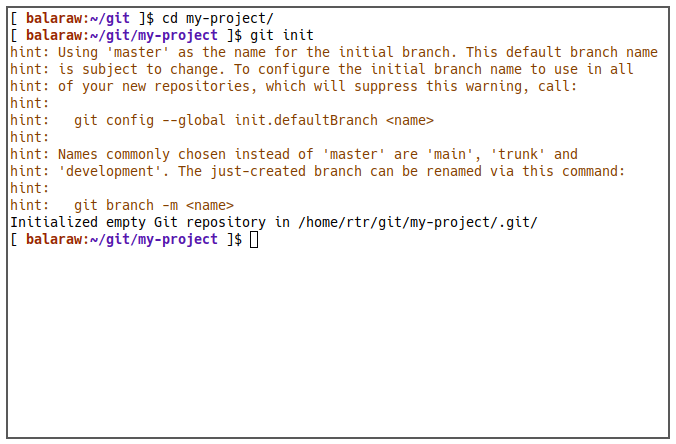
Once done, Git will create a “.git” folder in the root of your project directory. This will serve as both a marker for the Git program and a storage folder for all Git objects for that project.
Adding Existing Files to your Repository
With a working Git repository, the next thing to do is to import any existing files to Git. This is because Git does not track any files when you first create a new repository.
To do that, you can run the following command in your folder’s root directory:
git add .
This command will tell Git to include all files and folders in the current directory. You can then confirm this by running the following command:
git diff --cached
Also read: How to Clear Git Cache
Committing your First Repository
With your files now in the repository, the next thing that you need to do is to write those changes to the Git filesystem. This makes sure that it will properly tag and hash all the new files in your folder. In order to do this, you will need to “commit” the current state of the repository.
To do that, you can run the following command:
git commit -a
This will tell Git to write everything that it is holding in its cache to the virtual filesystem.
From there, Git will then ask you for a description about this specific commit. This will allow you to provide a brief explanation on what it contains as well as a way to easily distinguish this commit from others. In my case, since this is my first commit, I will just write “Initial Commit”.
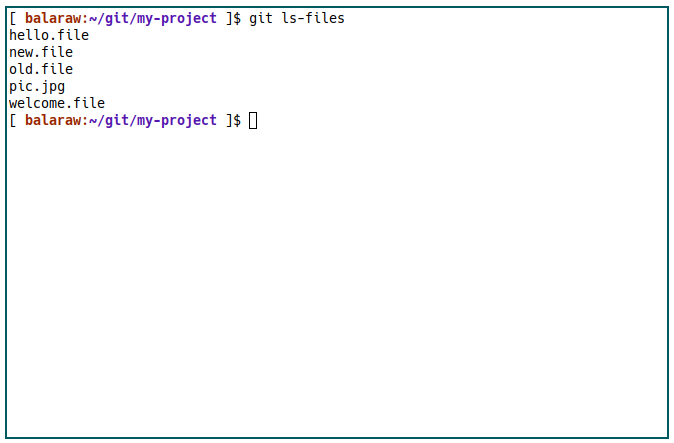
With that, you can now check if Git recognizes all the files in your directory by running the following command:
git ls-files
f during the above, Git throws an error saying it can’t recognize you, you’ll have to tell it who you are. Doing that is as simple as entering:
git config --global user.name "Your_Username" git config --global user.email "your_email_address@mailserver.com"
Basic File Operations in Git
For the most part, UNIX commands will work with Git. This means that you can use ls, cp, mv and rm on all files and folders inside a Git repository. However, there are a number of specific commands that you can use to easily manipulate Git objects.
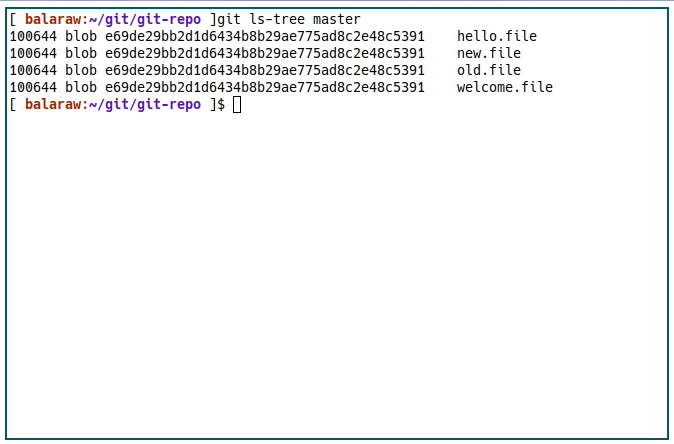
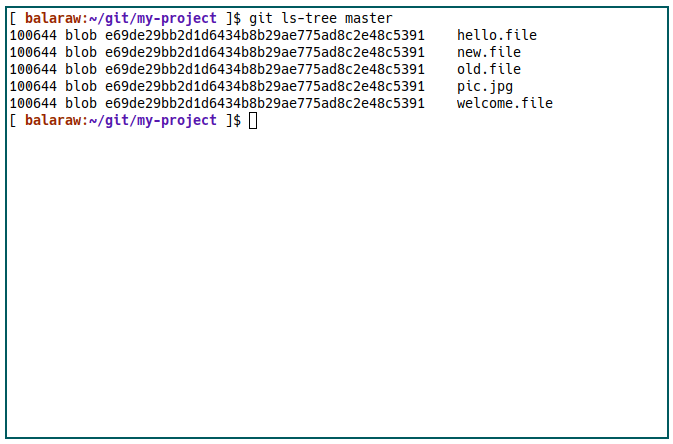
For example, you can use the subcommand ls-tree to view the contents of a specific Git tree as well as each file’s current hash value.
git ls-tree master
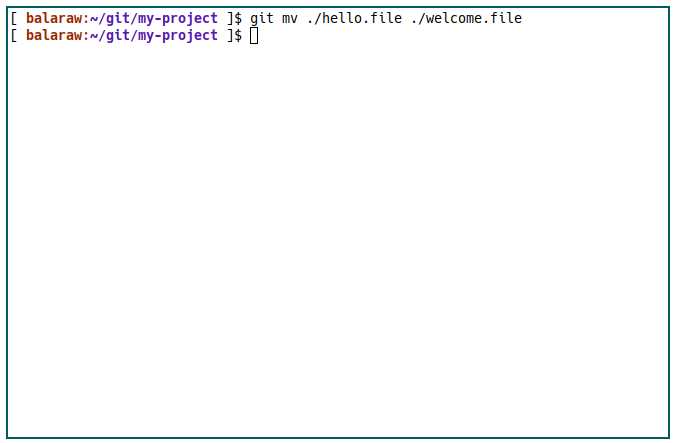
Another command that you can use is the Git version of mv. This allows you to move files anywhere within the repository and still retain their history.
git mv ./hello.file ./welcome.file
This can be helpful if you want to rename a file in version control but you also want to have the ability to revert that change through Git.
Knowing that, you can run the following command to rename a file without losing its history.
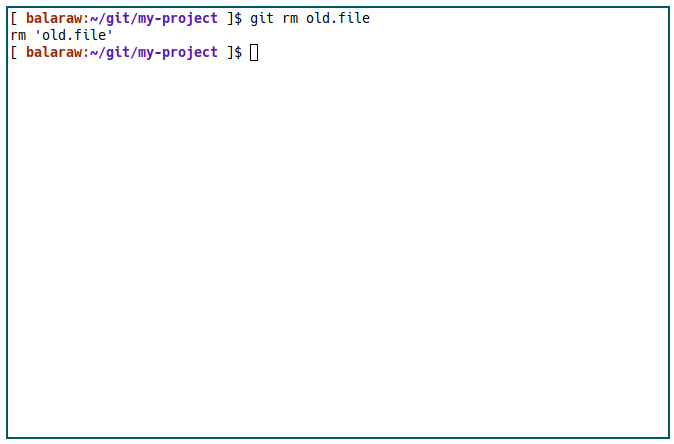
Lastly, Git also provides a subcommand for removing objects. Similar to mv, you can use a Git version of rm to remove a file in your current repository. Doing it this way allows you to cleanly remove the current object for that particular file.
git rm ./old.file
Cloning a Remote Repository
It is also possible to import a remote repository to your local machine. This is useful when you need to copy a different project over the network. Git provides you with the ability to clone an already existing repository.
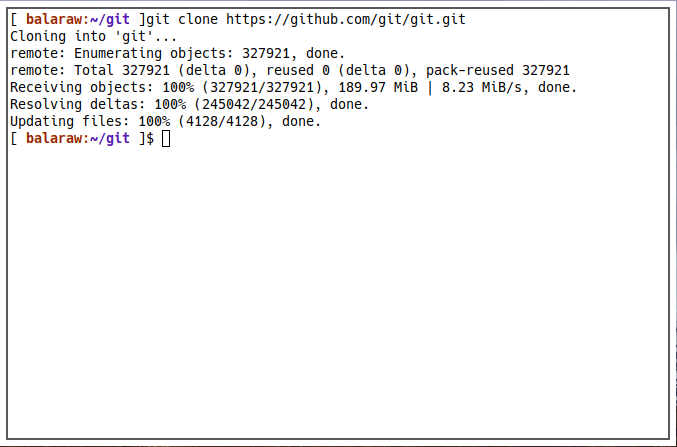
The way cloning works is that Git fully copies the tree of a remote project. This allows it to recreate the entire history of a repository as it exists at that specific moment in time.
git clone https://github.com/git/git.git
It is also possible to clone repositories that only exist in a local network. This is helpful if you are collaborating with other people over LAN. Further, the process of cloning a project in a local network is exactly the same:
git clone 192.168.1.100:/home/bob/awesome-project
Also read: How to Use Git Alias to Make Git More Efficient
Using Git for Online Projects
With that, another way of collaborating with other people is through third-party hosting. In this, you are using a remote service such as Github to host your project over the internet. This can be incredibly useful if you need a quick and easy way to distribute your work to a large audience.
Not only that, a service such as Github also streamlines the process of creating and maintaining a repository. As such, it is a powerful service if you intend on doing collaborative projects with other people over remote networks.
Creating your First Online Repository
Knowing that, starting a repository through Github is incredibly easy. Once you are logged in to your account, the site will redirect you to your personal landing page.
This page will display the latest updates on the projects that you are currently following. That includes a brief history of all your contributions to other projects.
From here, you need to click the “+” sign beside your profile picture. This will bring up a small drop-down menu where you can choose a number of actions for your account. You need to, then, click the “New Repository” link from that menu.
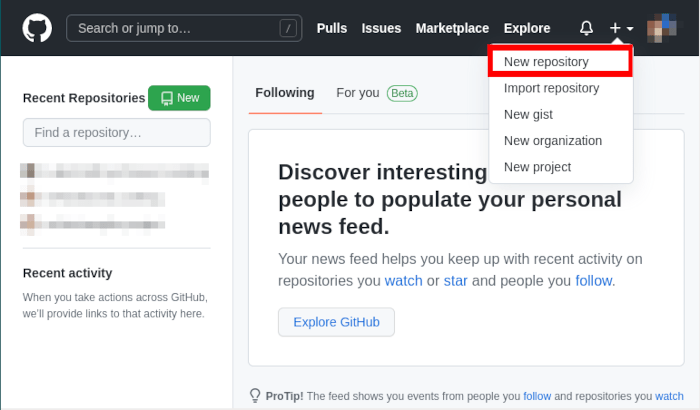
This is where you can specify the details for the project that you want to do online. From there, you need to set a number of options to fine tune your project.
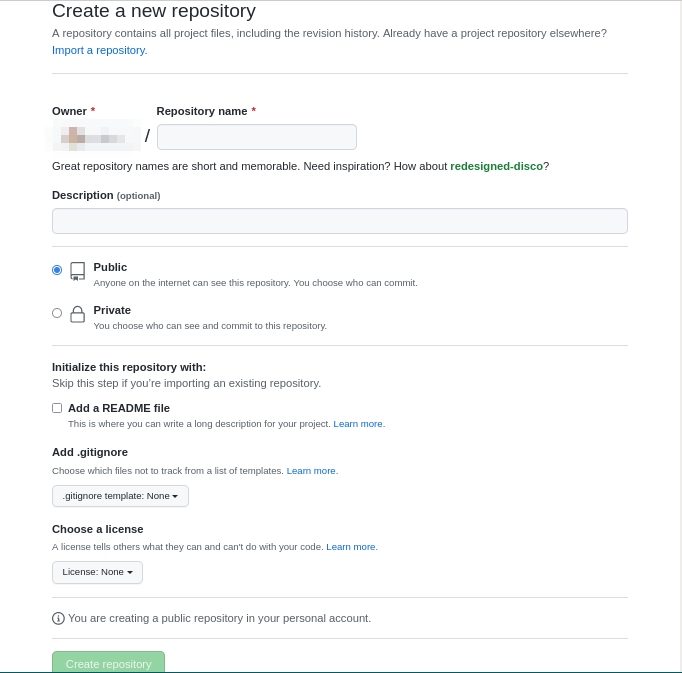
First, you need to provide a repository name for your project. This will serve as a name where other people can search for when looking for your repository.

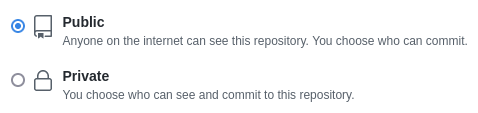
Next, you need to set the privacy settings for your project. You can choose between Public and Private. A public repository allows other people to search for your project online while a private one gives you the ability to only share it to a few people.
Lastly, you need to click the “Create Repository” button to finalize your new project.
Also read: How to Delete a Local and Remote Git Branch
Linking Github to your Local Machine
With that, the next thing that you need to do is to link your local machine to your Github account. In order to do this, you need to do two things:
- First, you need to create an SSH key for your machine. This is a short cryptographic key that you can generate locally in your computer.
- Lastly, you need to tell Github your current SSH key. This allows your machine to have a fixed identity to Github. In turn, it uses this identity to verify you whenever you update your repository.
Creating your SSH Key
If you are using Debian or Ubuntu, you can install SSH using apt:
sudo apt install ssh
From there, you can then run the ssh-keygen program to create the ssh key:
ssh-keygen -t ed25519 -C "ramcesred@domain.email" ssh-add /home/$USER/.ssh/id_ed25519
Linking your SSH Key
Go back to your Github Dashboard, click your Profile Picture and then Settings.
This will bring up the general settings for your Github account. From here, you need to click the “SSH and GPG Keys” link under the “Access” section on the page’s left hand sidebar.
Click the “New SSH Key” button beside the “SSH Keys” header. This will then load the key setup page where you can copy the contents of your new SSH key.
Open your keyfile (in my case, From there, id_ed25519.pub keyfile in “~/.ssh” directory) in a text editor. Copy the content and paste it to Github.
Pushing Local Commits Online
The last step is for you to upload the contents of your local project online.
On your local machine, go to the Git folder and run the command:
git remote add origin git@github.com:ramcesred/my-project.git
From here, you need to then make sure that your local project is currently at its master branch. This is so that Git will copy the proper version of your project. With that, you can ensure that by running the following command:
git branch -M main
Lastly, push the current state of the project online:
git push -u origin main
Congratulations! You now have a basic working setup for Git projects. Not only that, you also now have a basic idea of how Git works and how you can make it work for you.
Also read: How to Install Git and Git Bash in Windows
Frequently Asked Questions
Is it possible to get the changes other people have made to my online Git project?
Yes! It is possible to copy the changes that other people have made to your online repository. You can do this by pulling from your remote origin.
You can easily pull any updates on it by running the following command: git pull origin main
What are some of the issues that I should look out for when using Git?
One of the biggest issues of using Git is that it takes a lot of space when storing binary files. That includes any file that are not encoded in plain text such as images, office document formats and compiled programs.
This is mostly because the compression and hashing algorithms that Git uses to store objects heavily favor plain text files. It is possible to include binaries under version control, however, it is good practice to avoid using them with Git.
Is it possible to not include files in a Git tree?
Yes! You can easily exclude files from a commit. You can use a “.gitignore” file to tell Git that you do not want to include certain files.
This is a hidden text file that you create in your repository’s root folder. In this, you include the relative paths of files and directories that you want Git to ignore.
Image credit: Unsplash